
 Tim Oates’, Chair of the Expert Panel responsible for the recent review of the National Curriculum, has posted an interesting video about assessing education without levels. I agree with large parts of the video but suggest that in some respects, Oates’ model is unhelpful
Tim Oates’, Chair of the Expert Panel responsible for the recent review of the National Curriculum, has posted an interesting video about assessing education without levels. I agree with large parts of the video but suggest that in some respects, Oates’ model is unhelpful
I am grateful to Harry Webb (@websofsubstance) for the link to Tim Oates’ recent video explaining the report of the Curriculum Review body, which resulted in the abolition of levels in UK schools.
No-one, either individual or committee, is going to get everything right. The first thought that occurs to me from viewing Oates’ critique of our current assessment regime is “how could people—how could the whole system—get it so wrong last time round?”—and if people got it so wrong last time, how can we be so confident that they will get it right this time round? Those who produce recommendations for politicians to implement need to be very cautious when the harm caused by mistakes at this level can be so great. Even if the drift of those recommendations is substantially correct, everyone involved in such processes should welcome a continuing debate, which is the only way that we will avoid spending the next couple of decades up yet another blind alley.
Formative and summative assessment
After giving a brief introduction to the Curriculum Review, Oates turns to the question of assessment in the new curriculum (4:49), listing a number of qualities of good assessment, such as reliability and validity. At the end of this discussion, Oates suggests a tension between the first principle, reliability, with the last principle, utility:
At Cambridge we could make assessments incredibly reliable – but they would be 40 hours long and incredibly expensive. So you need to keep utility in mind.This assumes that the 40 hour assessment would be “time out” from productive teaching and would not be reusable: an assumption that rests on the separation of formative and summative assessment. If ed-tech is in the future able to create systems of continuous formative assessment that provide useful forms of learning activity (such as practice), useful feedback for students, useful diagnostics for teachers, and at the same time offer the sort of reliability that can only come from repeated sampling—if, in other words, assessment was largely integrated into the processes of teaching and learning, then 40 hours would not by any means be too long.
This is actually a point that Oates goes on to address himself (8:30):
We have really good research which shows us that we have underdeveloped formative assessment – and we need to work on that…This point represents an initial, but perhaps symbolic, skirmish. I am very much in agreement with Oates’ objectives, but not always with all of his assumptions about how this will work in the future, given that we are able to realise effective forms of education technology. In these circumstances, we will find that formative assessment does not need to be put into a separate box from summative assessment: there is no tension in principle between delivering reliable assessments and supporting teaching and learning at the same time.
Teaching to the test
Oates’ next point is that teachers spend too long teaching to the test and that this tends to distort the curriculum (9:02)
In fact if you ask teachers, have you looked at the National Curriculum in KS3 and KS4, they tend to say “No, I haven’t done it for ages because of course we teach GCSE and History and we are dominated by the specification for that particular qualification. So, we really tend to think about assessment first in this country and we tend to think about curriculum second.This could be seen as an extension of his last point: teaching to the test is only a problem if you see the test as a summative assessment which takes the student away from productive learning. But there is also a more fundamental point, which assumes that the true aim of education is not encapsulated by the process of assessment at all (9:26):
Remember the assessment principle: if an assessment is valid, it has to focus on particular constructs. Those constructs are the things in the curriculum. We need to put curriculum first. Assessment should follow.Putting the curriculum first and assessment second means, according to Oates, focusing on “constructs”.
Constructs
Oates’ explanation of the term “construct”
What, you might ask, is a construct? Oates explains the term as follows (11:10):
Why do we call it a construct? Well, I can’t see with some sort of microscope that a child has understood the conservation of mass. What I can do is ask them some questions and I can see what they’re doing. I can ask them to draw something and I can ask them to produce something, which gives me an idea of whether they understand conservation of mass. I can observe them on a series of occasions and from that I *construct* the idea that they understand conservation of mass. So the idea of construct is important: it tells us that we need to observe somebody in order to make a judgement…we understand that we construct an idea about somebody understanding it.At the heart of this passage is what I think is a really important idea, which is poorly understood in education. At the same time, I do not think that Oates’ explanation of what is happening is quite right.
Problems with the term “construct”
The problem of conflation
My first problem is that Oates’ explanation of the term “construct” is conflating at least two separate things:
- the understanding defined as “conservation of mass”;
- the attribution of such understanding to a particular student.
Oates says that the assessor *constructs* the idea that a particular student understands the conservation of mass, missing the fact that this is a two stage process.
The problem of imprecision
My second problem with “construct” is that it is imprecise. We construct all sorts of things: houses, motorways and alliances, for example. Even within the domain of education, we are likely to construct presentations, lesson plans and different sorts of ideas and theories.
The problem of truth
My third problem with “construct” is that the term is associated with a branch of post-modernist thought that suggests that it does not matter whether an idea is true or not, all that matters is that I have constructed it. When I say that Jonnie has understood the conservation of mass, I am not just asserting that I have created this idea: I am also asserting that it is true. In this respect, it does not help that the term “construct” does not provide any information about what it is that I have constructed or what it is claiming to be true.
Preferred terms
My preferred term is “capability”. I shall explain my reasons for preferring this term over the course of this essay but for now I want to distinguish between five different aspects of capability, as it is used to measure attainment:
- the concept, e.g. of the preservation of mass, which exists “out there” in Plato’s intelligible realm and which we all perceive in our different ways, “through a glass darkly”;
- the symbolic representation of that concept in terms that are sufficiently precise that it can be applied consistently;
- the expression of a particular degree or quality of that capability, for example as a Boolean value (true/false), a piece of text, a grade or a numeric value like a percentage;
- the attribution of such an expression to a particular student, as in “Jonnie has a good understanding of the conservation of mass”;
- the attribute, probably buried deep in Jonnie’s neural pathways, that gives him the characteristics that I perceive in him and justifies my attribution.
So we already have three different “constructs” (representation, expression and attribution), as well as two elements of reality (concept and attribute) that float for ever just beyond our grasp.
Common ground
I do not want to dwell too much on my quibbles with the term “construct”, as I agree with the basic point that Oates is making. Not only do I agree but I believe it is very important. Below is a diagram from a presentation that I made to a ISO/IEC working group, using my term, “capability” rather than Oates’ term “construct”.
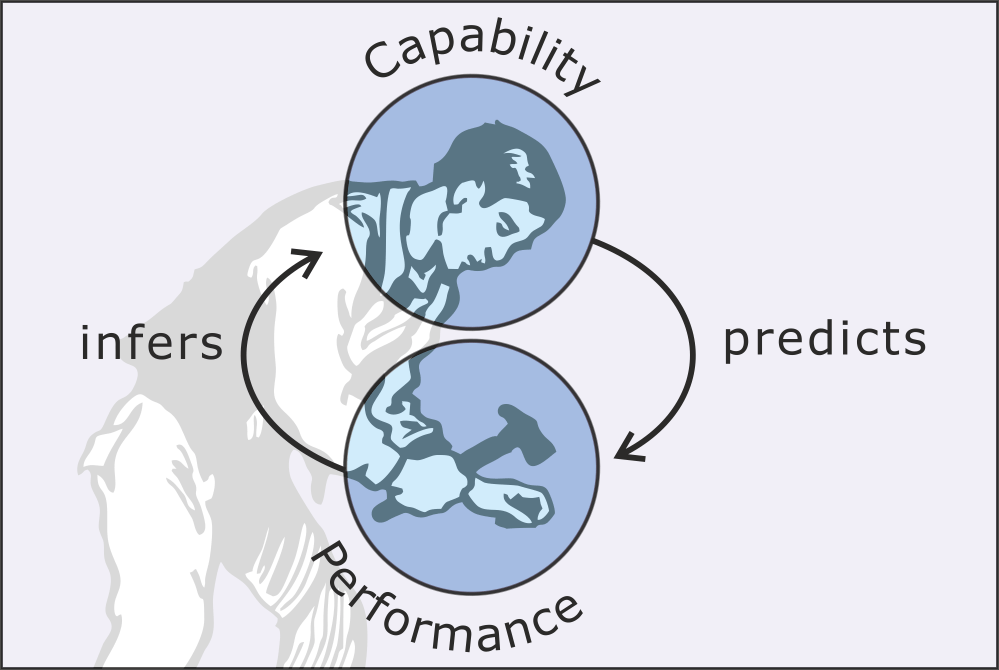
The capability (or to be more precise, the capability attribute) is something that makes the carpenter good at carpentry. It is what Aristotle, discussing virtue in his Nichomacean Ethics, would have described as a “disposition”. But as Oates says, this construct/capability/attribute/disposition cannot be observed directly with some sort of microscope. The only way you have of detecting this characteristic is by observing what they do—or as Oates says, the answers they give and the things that they produce. I call these actions a “performance”—a term which encapsulates an expectation of producing a certain sort of outcome.
What matters at this stage is the relationships between the performance and the capability. Having assessed a student’s performance, I might infer the existence of a capability. By attributing such a capability to the student, I am effectively predicting the ability to produce a range of similar performances in the future. If this prediction turns out to be incorrect (for example, because the first performance was a fluke or was tied to a limited set of circumstances or the student’s capability degrades) then the attribution is thereby shown to be incorrect. The performance can be observed, the capability cannot—but ultimately it is the lasting capability and not the transient performance that is of interest.
Oates’ argument is that the curriculum is made up of abstract construct/capabilities (or at least the “educational objectives” which express an intention to develop those capabilities) and not the sort of concrete but particular performances which are sampled by assessments. The validity of the assessment depends on its ability accurately to target the construct: and if the assessment is the construct, then it is valid by definition—which is a logical tautology (i.e. meaningless).
I think the importance of this point can hardly be over-stated because it is so often ignored. Students are routinely awarded exam results because of what they did and not becuase of what it is judged that they can do. But to make sure that we really understand the point, we need to make sure we are clear about what exactly is this thing that Oates calls a construct?
Oates’ examples of “constructs”
In order to explain the notion of a construct, Oates’ provides some examples (12:04):
What are constructs? I’ll list a few. “Multiplying two three digit numbers together” that’s a construct, and I can ask a series of questions of a child, ask them to do some things, which can give me an idea whether they can do it adequately and can do it in a range of settings.Indeed, this construct is pretty straightforward and there is little scope for disagreeing how you would go constructing an assessment (whoops, there’s another “construct”) to support it (though even in this example, different people might still disagree about how many times, over what sort of period, and in what range of settings this capability would need to be observed before one could infer mastery).
Here is another example (12:36):
Lets look at another construct in the National Curriculum: “Reading a wide range of books for pleasure”……and if you want to know exactly what this construct means, Oates explains it a little later (13:15):
So let’s look at “reading a wide range of books for pleasure”. They are “reading”, they are not just scanning text – they’re reading and extracting meaning from it. They’re reading “a wide range” of books—so that’s a construct too—and they’re “books”, they’re not other things. And they’re “enjoying” it – so, that’s a construct too. We put them all together and we get a very specific construct that we can assess.Is it really that specific? This construct strikes me as being far less clear—and no extra clarity is introduced by going through the definition one word at a time. At exactly what point does “reading” become “scanning” and how would you create an assessment to make this distinction and how confident could you be that your assessment would produce a similar outcome to somebody else’s assessment, based only on a reading of this short descriptor? How would you define “a wide range” both in terms of quantity and quality of reading: one book a week? one book a month? one book a term? and how many different, authors, genres, nationalities and periods are required to satisfy the requirement for “a wide range”? And what exactly is the definition of a “book”? Does it not count if it is on the iPad or if it comes in at under 100 pages?
I would anticipate that different teachers would make wildly different interpretations of the definition, however simple and apparently straightforward it may initially appear to be. And we are still in relatively straightforward territory. A “construct definition” (a.k.a. Statement of Attainment) picked randomly from the 1988 National History Curriculum, required that students should be able to
distinguish between different kinds of historical change (AT1 Level 5a)a criterion with almost no indication whatsoever of the quality of work or sophistication of cognitive function that is required.
Terry Freedman has recently made a very similar argument on his blog:
What does the description actually mean? For example, a statement like “They use ICT to structure, refine and present information in different forms and styles for specific purposes and audiences.”, from the old ICT Programme of Study can be open to question. What, for instance, does “different … styles” actually mean? If a student changed the fonts in a document and saved it under a different name, would that count? Presumably, just changing the font, which is really easy, wouldn’t be the issue. Rather, changing the font to a specific font, for a particular type of audience, would be what matters. (That is, of course, if you think font-changing is relevant in the first place.)This problem with the obscure descriptors does not appear to have been solved by Tim Oates’ new terminology of “constructs”. So what does Oates think are the problem with levels, if it is not enigmatic criterion descriptors?
Levels
Oates’ problem with levels
Oates suggests that levels do not meet the requirements of validity and “construct integrity” (14:30) because there are three separate “models” of assessment practice:
- Levelling by score achieved on a compensation-based test;
- Levelling by best fit to the level descriptor;
- Levelling by threshold.
I am going to ignore the third of these issues, which strikes me as being a separate type of issue that is not comparable to the first two options. So I will consider only the first two points, which are what I would call different assessment methods. In the case of a compensation-based test (15:24):
You get level 3 on a KS2 test by achieving a certain number of marks. The thing is you don’t know where those marks have come from. They may have come from items which are targeted on higher level content in the national curriculum or they may have come from marks which are derived from the lower level targeted items…this is a known problem with compensation-based tests.Apparently this is not in itself such a big problem because the real difficulty arises not from any intrinsic difficulty with compensation-based tests but because there are other ways that are also used to assess levels (16:29):
That would be OK because we could deal with that problem as long as there weren’t other co-existing models of how levels are derived existing in the system and it’s the co-existence of the different systems that creates the problem.In the case of the second model, best fit levelling, this (16:48):
was present in the APP work (Assessing Pupil Progress) model, and that’s where teachers and pupils look at their work and say, “OK. This fits the level 3 descriptor”. Now, the problem there is there may be some real weaknesses in the child’s attainment, some key things that they haven’t acquired in sufficient depth, and that gives the misleading impression that they are ready to move on. But it really is different to the score on a compensation-based test.A mis-diagnosis of the problem
It strikes me that there are two important inconsistencies in what Tim Oates is saying.
- First, he starts by saying that a construct is qualitatively different from an assessment, that the curriculum is composed of constructs and not assessments; but then he says that the major problem with levels is that the constructs represented by the level have been assessed in different ways. If the construct really was different from the assessment method, then the existence of multiple assessment methods addressing the same construct would not be a problem. If on the other hand the construct can only be assessed in one way, then the construct is dependent on the assessment method and the two are logically and topographically identical.
- Secondly, he says that the problem is that there are two different models that produce different and results and then, when he comes to explain what each of those models is, he admits that there are also inherent problems in both approaches. If both assessment methods are intrinsically flawed, then one cannot say that, were the assessment methods not flawed, they would not then agree. If I measure the temperature in my bathroom with two different thermometers, both of which is faulty, I cannot be surprised if the readings do not agree and have no grounds for blaming the fact that I took two readings, rather than relying on one. I would say that it is the co-existence of the different assessment methods that reveals the problem. If you have a single inaccurate assessment method you may never notice that anything is wrong—but that does not alter the fact that your assessments are inaccurate.
To illustrate these problems with Oates’ analysis, it is worth considering the circumstances in which the two different assessment methods (compensation-test scores and best fit to descriptors) would produce the same result, assuming that both assessment methods are valid and are properly executed and that the assumptions attached to the level descriptors are also valid.
Take the first four Statements of Attainment from Attainment Target 3 of the 1990 National History Curriculum (The use of historical sources):
- Communicate information acquired from an historical source;
- Recognise that historical sources can stimulate and help answer questions about the past;
- Make deductions from historical sources;
- Put together information drawn from different historical sources.
This sequence of four descriptors presumes a particular developmental model: that whatever sort of performance is described by level 3, “make deductions from historical sources”, it is more difficult than level 2, “recognise that historical sources can stimulate and help answer questions about the past”. If this were true, then the results from compensated tests and best fit assessment methods would correlate.
Assume that all my students are first given levels by best match to the level descriptors, and then given an assessment with 40 items, with 10 items for each of the four Statements of Attainment. A student who is at level 2 should be able to do most of the questions that target levels 1 and 2 but very few of the questions targeting levels 3 and 4. This student will receive a score of 50% and will be correctly assessed as being at level 2. A student who is at level 3 should be able to do three quarters of the questions, receive a score of 75% and will be correctly allocated to level 3.
If on the other hand it is found that a large number of students are getting a selection of questions right from all four sections of the test, or are getting questions right from level 2 and not level 1, then either the questions do not properly target the Statements of Attainment, or the developmental model posited by the level descriptors is false. And if no-one has ever produced robust, quantitative evidence that best fit and compensated test scores do correlate, then no-one has any reason to suppose that the developmental model posited by the level descriptors is anything other than false.
If you have followed this argument, you will appreciate why I think that Oates conclusion is so unhelpful (17:45):
This issue of co-existing models is a real problem in assessment theory and practice and as assessment professional, we were very very concerned about these co-existing models in the system. It’s a problem because it means that “Level 3” means something different depending on what assessment you are using and who is making that claim that this child is level 3. That’s bad according to those original principles I laid down. Level 3 needs to have construct integrity. You need to know what having level 3 means because you’re going to do something as a result of that label.In fact, the existence of different assessment methods is a strength, not a weakness of the system. It allows assessors to achieve greater reliability and validity by correlating different sorts of assessment—and it also reveals problems with the sequencing models encoded into the underlying capability frameworks. If you achieve “construct integrity” by narrowing the range of different assessment methods being used, you are not solving the problem but hiding it.
How to communicate meaning
Verificationism
I am going to step away from Tim Oates’ video for a moment to explain a better way of creating consistent meaning in what I call “capability representations” and which Tim Oates calls “constructs”. Because it should be clear from the discussion above that the lack of meaning in criteria descriptors is at the root of most of our problems.
If (as my workman diagram above suggests) a capability is something that may be inferred by certain sorts of performance and which in turn predicts the production of similar performances in the future, then the meaning of the capability is given by the sort of performances with which the capability is associated.
This principle can be illustrated by referring to Einstein’s explanation of relativity in his 1916 idiot’s guide to to the subject. He asks his reader to imagine two lightning strikes that occur simultaneously at two different places along a railway track. He then asks the reader to consider what is meant by the lightning striking the two places simultaneously. Most of us would answer this question by giving a dictionary definition of “simultaneous”—but not Einstein. In accordance with Karl Popper’s theory of verificationism, Einstein insists that the only way to understand the true “meaning” of simultaneous lightning strikes is by specifying the experimental method by which one would prove or falsify the assertion that the lightning strikes were simultaneous. Einstein proposes an experimental method that runs along the following lines. You should erect two mirrors at the exact mid-point between the two (anticipated) lightning strikes, angled at 45% so that the light from both strikes will be deflected onto a light-sensitive detector placed on the side of the railway track. The lightning strikes are simultaneous if and only if the light from both strikes reaches the light detector at exactly the same moment. Einstein urges that if any reader cannot accept that this description of an experimental method constitutes the effective definition of what it means for the lightning strikes to be simultaneous, he should put down the book and stop reading (I will fill in the exact quote when I can find my copy of the book).
In the same way, the meaning of a capability representation (or “construct”) is not given by dictionary definition or a criterion descriptor but rather by a description of one or more assessment methods by which the existence of the capability can be shown.
When Oates identifies a problem with the interpretation of criterion descriptors, I can only agree wholeheartedly that this is a “very very bad thing” (21:03).
We looked at sub-levels, a, b, c, and found that there was real discrepencies in the way in which different schools and different people interpreted what these things mean. and if you have the same label floating around the education system but meaning different things to different people, that is a very very bad thing.The trouble is that this problem of poor definition stems from the very separation between descriptors and assessments that Oates is himself urging. The meaning of the levels must be given in terms of the methods of assessment with which they are associated. And when teachers tell Oates that they “haven’t [looked at the curriculum] for ages because of course we teach GCSE and History and we are dominated by the specification for that particular qualification”, their position is reasonable and Oates is wrong to suggest that they should be looking at the curriculum rather than the assessments. No-one can understand what the curriculum means until they see how it is going to be assessed.
Exemplification
“But hang on”, you will say. “At the top of this piece, you said that the separation of construct/capability from performance/assessment was vitally important. Now you are saying that it is the cause of all our problems”.
I answer that the separation between the two is indeed vital—but understanding the relationship between the two is also vital. It is true that the performance is not the same thing as the capability. Even though we cannot see or directly measure the capability, we believe that it really exists, both as an intelligible concept and as a real attribute, encoded somewhere deep in the subject’s neural pathways. We are talking about a real thing—not just a “construct”. And just because the subject has such an attribute does not mean he will inevitably produce a corresponding performance. There being “many a slip ‘tween cup and lip”, the attribute (or “disposition”, as Aristotle called it) is only predictive of a certain sort of performance. Nor is it predictive of (or defined by) a single performance. “Having leadership skills”, for example, does not mean that you can only provide leadership to one person in one context—it means you can perform in a wide range of contexts, many of which have not yet been envisaged. So it is better to say, not that the capability representation is defined by a set of performances, but that it is exemplified by a certain sort of performance. Because exemplification is a perfectly acceptable way of conveying meaning: Oates uses it himself in preference to definition when he says (12:04):
What are constructs? I’ll list a few.By using the term “exemplification”, I am suggesting that it is only by looking at a variety of valid means of assessing a capability representation that it is possible to answer all the questions I (and Terry Freedman) ask above about what a criterion descriptor really means. How many books a month and what sort of spread of genres is meant by a “wide range”? Look at the assessments—they will tell you. This, every teacher knows. But the assessments to which you refer for exemplification do not constitute the outer boundary of what the capability means: next time it is assessed, you might find your students facing up to a completely new sort of assessment. But it will only be a valid assessment (a term with which Oates’ started his talk) if the results from the new assessment, sampled at appropriate scale, correlate with the results from the existing body of assessments.
Exemplification is therefore the primary—but not the only—means of communicating meaning.
Types of relationship (part 1)
Sequential relationships
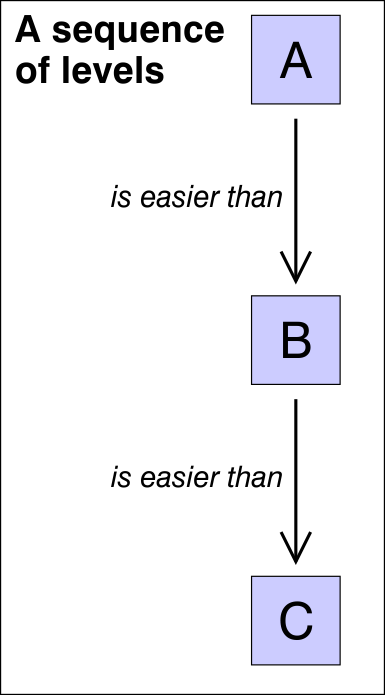
Capability representations may be related to each other (as are the separate Statements of Attainment in the History Attainment Target illustrated above). In this case, the capabilities are related to each other as they are given places on a single scale representing difficulty.
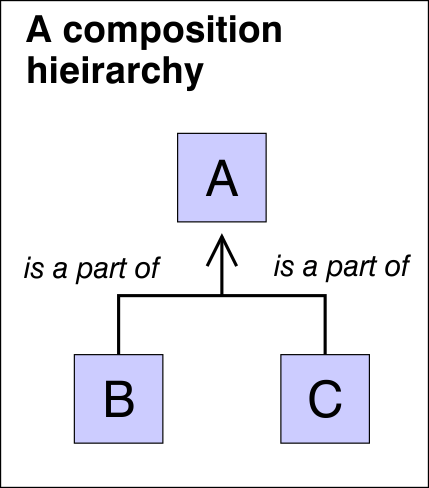
Compositional relationships
One of the instrinsic problems identified by Oates with “best fit” assessment against criterion descriptors is the difficulty of what to do when none of the descriptors fits well (16:48):
where teachers and pupils look at their work and say, “OK. This fits the level 3 descriptor”. Now, the problem there is there may be some real weaknesses in the child’s attainment, some key things that they haven’t acquired in sufficient depth.This problem suggests that the capability representations are not at the correct granularity—and this is a problem that Oates explicitly addresses at 20:32:
What schools do in parental consultations is they say “your child is at level 3″…but then they have the real discussion, which is about whether the child has understood the really fundamental things that they need to understand in order to progress. Whether they have understood the conservation of mass – they need to understand at that level of granularity.The problem with granularity can be addressed by decomposing high-level capabilities into subsidiary capabilities. In the diagram below, capability A is only mastered when all the subsidiary capabilities are also mastered. The attribution of this capability can now be tracked in greater detail and with greater accuracy.
Expressing capability
Another problem with “granularity” (a problem which Oates does not mention) is the problem of expression. The assumption behind criterion descriptors is that either a child has “got it” or they haven’t. But few capabilities are like that. There may be an intrinsic scale of achievement: for example, if you were to assert a capability at typing, you would probably express that capability in a combination of metrics that measured words-per-minute and errors-per-minute. That is two graduated metrics. This form of expression will be much more useful than one which simply says that you can or cannot type. The arrangement of binary criteria into sequences of levels could be seen as an attempt to create a graduated scale of achievement out of building blocks that are in themselves poorly adapted to measuring the sort of incremental capabilities in which education is interested. Creating flexible expression metrics is another way of creating a more detailed granularity to your capability data.
This point touches one reason that I use the term “capability” and not “competency”, which is often used in this context. The problem with “competency” is that it is binary. The pilot on your aeroplane is either competent or not competent in the role that he is performing. “Competency” is a term which has been handed down to education from the HR profession and, like so many hand-me-downs, it doesn’t really fit.
Once you allow capabilities that can be expressed using complex and graduated syntax, you are likely to find that the manner in which you express capability may coincide with the way in which you assess performance. 35 words per minute may refer to a particular performance or to a general capability. This point emphasises the close relationship between capability and performance.
Types of relationship (part 2)
I discussed above the importance of relationships between capability representations and mentioned two sorts of possible relationship: sequencing relationships and compositional relationships.
I would suggest that there is another way of categorising relationships, which is perhaps more fundamental still, and which I would characterise as the difference between modelling and mapping relationships.
Modelling relationships
Consider the sequence of descriptors in a framework of levels such as the History Attainment Target illustrated above; and consider the situation proposed by Tim Oates when a compensated test score does not correlate to an assessment by best fit to descriptor. As already discussed, the reason for this lack of correlation is that the sequencing model proposed by the level descriptors is incorrect.
There are two ways of resolving this inconsistency, which correspond to saying that either the compensated test score takes priority, or that the best-fit to descriptor takes priority. If you say that the compensated test score takes priority, you are in effect saying that the level descriptors form a sequence of difficulty by definition. The level descriptors may be treated as illustrations only—but if there is any lack of clarity in what the level descriptors mean, you will not go wrong if you assume that the level of work required needs to get more difficult at every level.
This is what I propose to call a modelling relationship: the relationship between the capability representations are part of the definition of what the levels mean. The compositional relationships shown in the figure above would also normally be interpreted as modelling relationships. In most cases, you would not need to provide any descriptor for the parental capability A: it is enough to know that a student would be considered as having mastered capability A if and only if he had mastered the subsidiary capabilities B and C.
Mapping relationships
If the level descriptors are prior to the sequencing relationships, then the sequencing relationships between the levels are what I would call mapping relationships: they assert a relationship which the data may or may show to be valid. Another sort of mapping relationship would commonly assert the equivalence of two different representations.
Summary of relationships
Modelling relationships are true by definition and help define the meaning of individual capability representations. It follows that modelling relationships will need to be declared and controlled by the publisher of the capability representations and any containing framework.
Mapping relationships are contingent assertions which may or may not be true. They may be declared by anyone and may be proved or falsified by looking for correlations in the data.
Managing multiple assessment methods
Again, you might object that I said at the top that a single capability might have many different assessment methods, each of which provides an exemplification of what the capability means, but none of which provides a complete definition. This leaves open the possibility, as illustrated by the example above, that a single capability may be associated with multiple assessment methods which conflict. In these circumstances, I would agree with Tim Oates that the capability representation would have to be judged as lacking “integrity”. If you accept my argument that the assessment methods exemplify the meaning of the capability representation, I think you would have to go further and say that it lacked “meaning”.
Given that a single capability representation is not associated with a closed set of assessment methods and that new assessment methods may be proposed after the capability representation has been published, it follows that the meaning of the capability representation is not defined but is what I would call “stewarded”. Stewardship requires a steward—a point of authority or control. But I suggest that a good steward will also engage in a conversation with a wider community. Such a conversation is likely to involve the publication and discussion of exemplification materials: in other words, the sort of moderation and reporting that awarding bodies commonly do already. The quality of such stewardship can be assessed by looking at the consistency with which the stewarded capability representations are used.
It is not desirable, in my view, that the meaning of our capability representations should be stewarded by the state. The role of the steward is to ensure the integrity of its own capability representations, not to inhibit pedagogical innovation by dictating a single conceptual model of capability. For this reason, it would be preferable to have multiple publishers of capability representations, many of which will address similar competency concepts.
This double-de-coupling allows for two different ways of accommodating multiple assessment methods:
- either the publisher/steward of a single capability representation may allow for multiple ways of assessing and expressing a single representation, ensuring that these different assessment methods are consistent;
- or that same publisher/steward (or different publishers) can publish different representations, each of which be associated with different assessment methods and which can be mapped to each other by mapping relationships, the validity of which can then be tested by the data.
Summarising a new terminology of capability
I have been intending to write a series of posts on “measuring learning”, which would introduce the terminology of capability on which I have touched in this post. I will still get round to writing the full post but in the meantime, I include a UML diagram which summarises the terminology that I have been using in this post. I will not prolong this post by stepping through the diagram but if you have been following this post, and even if you are not familiar with UML, you should not find the diagram too hard to read, so long as you click on the thumbnail so that you can view the enlarged version.
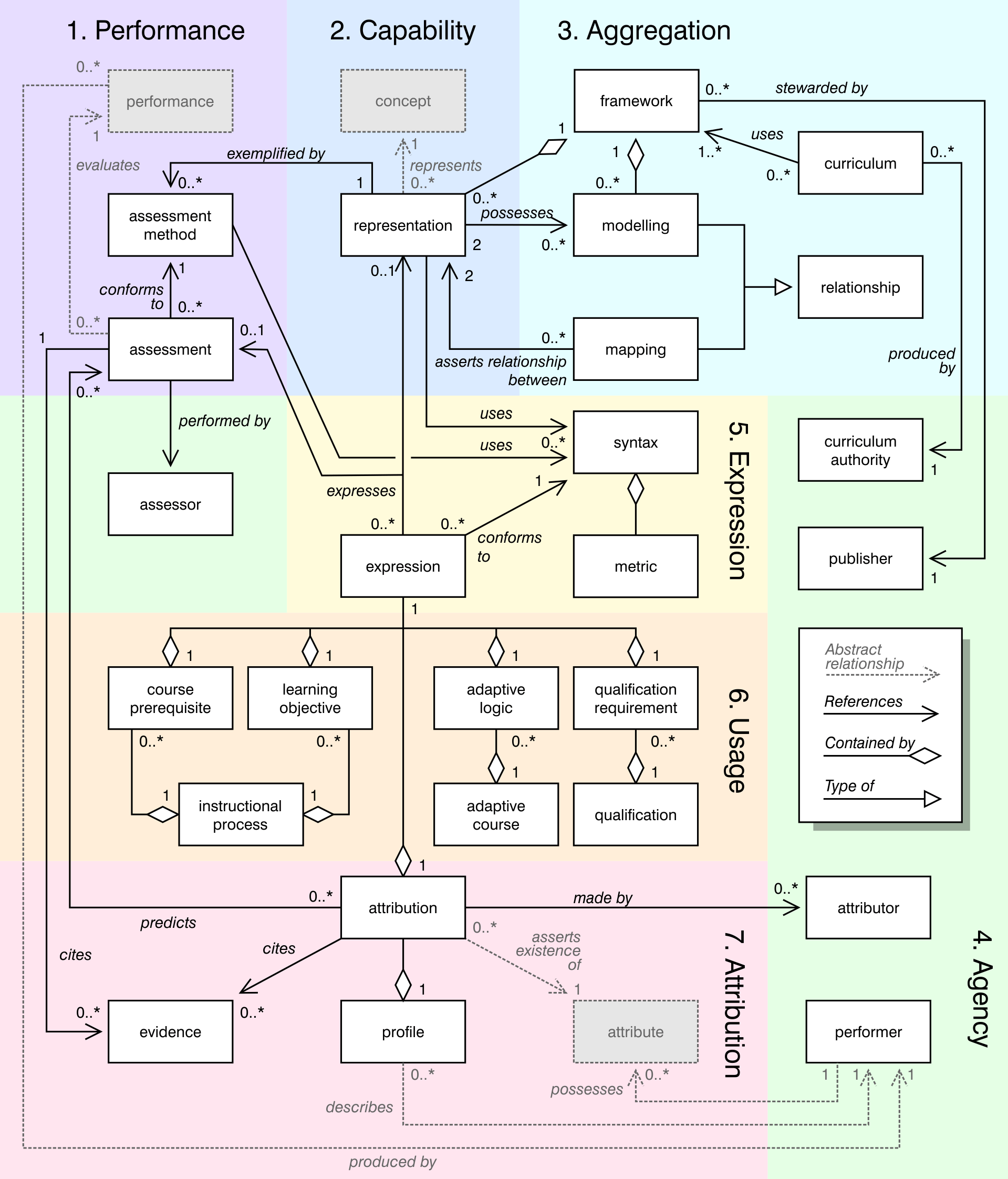
Many of the problems that I am trying to identify in this post stem from the lack of an agreed and consistent terminology that is commonly understood and shared between teachers, assessment professionals and government. The reason that I present this terminology in the form of a UML diagram is that it’s significance does not lie primarily in the individual terms chosen or their definitions. Although I believe “capability” is a better term than either “competency” or “construct”, I am happy to use either of the other terms, if doing so will help communication. The real significance of any terminology lies in how the individual terms relate to each other to create a coherent intellectual model.
In the standards world, there are a number of initiatives progressing at the moment to address the problem of encoding what is generally referred to (in my view mistakenly) as competency data. Such data standards are essential if we are to unlock the potential, much anticipated, of “big data”. But almost all of these initiatives are, in my view, deeply flawed—and one of the key problems, I believe, is that the problem itself is poorly defined. That is why this taxonomy could, in my view, be really helpful.
On the back of the assumptions which are encoded into the terminology proposed above, I want to make a couple of further comments about some of the conclusions that Tim Oates draws from his discussion of levels.
Problems with Oates’ conclusions
Curriculum and pedagogy
The first revolves around the use of the term “curriculum”, which I believe is used rather loosely by officialdom to refer both to the aims of education and also how those aims are to be delivered.
Oates refers, for example, to the fact that (37:04):
The reason that Primary is now laid out on a year-by-year basis is not that it’s a statutory requirement to teach this content year-on-year—because the statutory requirement is still attainment at the end of the key stage. No, we laid it out year-by-year to show the way in which children can progress the conceptual content—the underlying learning progressions. Now, this is very well evidenced from research.So the curriculum review committee extended its remit beyond defining what students should learn by the end of the Key Stage, to suggesting how they should learn those things, at least in respect of suggesting the order in which they should learn them. According to my understanding of “curriculum” as a collection of learning objectives, this question of sequencing relates to pedagogy and not curriculum. I would prefer to refer to the programme designed by teachers to address the curriculum as a “programme of study” and not a curriculum.
It may be that the importance of underlying learning progressions is be very well evidenced from research but the nature of those progressions in all the different subjects is very poorly researched. While I think it is entirely reasonable for the education service to be told in statutory instruments what they should teach, it seems to me to be highly problematic to use those same statutory instruments to tell them how they should teach—because encoding such pedagogical issues in statutory regulations inhibits the sort of pedagogical innovation that education needs so badly.
Two points already made in this post should highlight this concern:
- as I remarked at the top of this post, if the designers of the last curriculum could get it so wrong, how can we be so sure that the designers of the current curriculum have done so much better?
- Oates’ proposal to restrict the number of alternative assessment methods would have the effect of concealing incorrect sequencing models, such as the one that his committee has brought as close as it possibly can to being associated with the curriculum, which is a statutory instrument.
There may be some sequencing decisions that curriculum designers cannot avoid taking, of course. If there are statutory assessments at the end of every key stage, curriculum designers need to decide what learning objectives to put into KS2 and which to put into KS3 and KS4. But the more detail is included in the curriculum, the less scope there will be for the development of new, more innovative, and more effective pedagogies and sequencing models.
How much can teachers do?
The second of Oates’ conclusions that I question is his assumption that teachers can master the skills required to make this work. In the final section of the talk, Oates says (43:11):
It’s important for all teachers to grasp the principles, the ideas which lie behind high quality assessment—for all teachers to become in their own right assessment experts.He then suggests that this is happening already (44:18):
A whole range of schools are getting together in really exciting collaborative arrangements to devise what I see as highly effective approaches to developing good assessment without levelsTo consider whether this is really realistic, it is worth re-winding a little and considering how Oates describes the current levels of dysfunction. For example, far from being assessment experts at the moment, the overwhelming proportion of teacher judgments of student capability are currently completely unreliable (19:04):
We asked Secondary Schools, do they trust the results coming up from Primary School and regrettably, almost universally, they said that they didn’t.It seems like a big ask to expect the profession to transform itself in one leap from almost universal unreliability to a profession of assessment experts.
Furthermore, when the Curriculum Review Committee suggested including more practice in the Maths Curriculum (again, conflating curriculum with pedagogy—but only for the sake of what one would assume amounted to stating the blindingly obvious), they were met with determined opposition from the profession (34:22):
When we introduced the idea of more practice in the Mathematics curriculum it kind of produced an uproar with those with whom we consulted and there was a real risk that it was going to be scratched out of the draft but we looked at it really systematically and the reason that people were concerned about it was that a lot of the practice of Mathematics in our country is just dull repetition and that’s not the way that practice of particular Mathematical techniques plays out in other systems around the world. If you look at Singapore textbooks, they do loads more practice but that practice is really interesting and it varies systematically.Not only does the profession oppose practice—but the reason that it opposes practice is that when the principle is applied by the profession, the outcome is dull and repetitive. That is because creating effective and stimulating practice is really difficult: it requires considerable subject knowledge, time, piloting and incremental optimisation. The key word in the extract above is “textbooks”. Singapore succeeds where Britain fails because it relies on professionally-created instructional resources and does not rely on front line teachers to churn out home-produced, low grade worksheets (see my recent post Textbooks for the digital age). But the culture of the profession is not just hostile to good pedagogy—it is also hostile to the kind of division of labour that is required to produce the high-quality resources required to underpin good pedagogy.
Oates does not pick up his own reference to textbooks but suggests, to the contrary, that good questions need to be authored by front-line teachers (37:38):
Well, I’ve been into schools which administer some really thoughtfully devised tests – devised by the teachers because then they can set items (questions) which really link to the key constructs on which they have been focusing, which use the contexts which they have been using in their teaching.The reason, according to Oates, that the tests need to be devised by the teachers is so that the teachers can then assign tests which are appropriate to what they are doing in the classroom. But this is a non-sequitur: I don’t have to have created a test (or item, question or activity) in order to be able to assign it.
To be fair, Oates does suggest that teachers should be able to draw on the work of others (40:36):
I think we need higher density assessment, much more of it, but of the kind that I’ve been suggesting. Probing assessments. Probing questions in the classroom. Assessments put together by teachers, perhaps drawing down from the web those questions which they think really match the constructs on which they have been focusing…ideally I’d like a big, pull-down bank of items available from the web.I entirely agree with Oates about what he calls “higher density assessment”—assessment that I would describe as breaking down the barriers between teaching and assessment and between formative and summative—that is where I started this essay. But I do not think that banks of question items will deliver the experiential or pedagogical richness that such an ambitious vision requires. Banks of question items will not move us much beyond dull worksheets or, if you use digital media, with an updated version of the 1990s ILS systems. What we need are not questions, not items, but digitally-mediated activities: creative, social, exploratory, interactive. These require not just teacher-authored questions but a whole new layer of adaptable, interactive software—resources that are far beyond the ability of front-line teachers to produce. This is the point at which the pedagogical and assessment expertise of someone like Tim Oates needs to meet and cross-fertilize with the potential of ed-tech.
It is a common assumption that, if you give teachers the capability to draw on the work of others, the “others” on whose work they will draw will be other teachers. But once teachers have the capability to draw on the work of others, they can draw on the work of anybody—including new types of supply industry with the sort of technical and pedagogical expertise that the teaching profession does not, cannot possess.
Nor are static learning resources enough. Teachers also need to monitor outcome data and manage feedback. These were the recommendations, described by Professor Rob Coe as “impeccable”, of Assessment for Learning. But over the last decade, teachers, following traditional methods of CPD and classroom delivery, have shown themselves incapable of delivering such feedback effectively. Delivering good feedback is dependent on good monitoring (37:36):
What sort of data do these things produce? Well they produce marks, and ticks and crosses, where children have understood things and where they haven’t. I went into one school where these tests were being administered at half term so you could do something with the results in the remaining half of the term to focus on the things that children were struggling with. And you found that the red “x”s were concentrated all on particular things which led the teacher to think, “Hmmm, we really need to focus on these things because they’re not getting it”.The scenario described by Oates in this extract sounds to me at once clunky and unsustainable. According to this model, data on student progress is collected once a half-term, which in my view is not nearly frequently enough to underpin agile teaching that quickly address cognitive deficits. And it is clear that the reason the tests are administered at half term is to allow teachers to use a significant proportion of their holiday to mark the results and to adjust their teaching plans for the following half term accordingly—a set of demands which is hardly going to be conducive to rolling out this model across the service. If such an approach is going to work, these processes need to occur continuously and automatically, not manually and intermittently.
Now Oates sees the potential for technology to help with this process, through the mean of “big data” (38:38):
And its loads of data…and you can slot them into management systems and you can monitor how individual children are doing, how groups of children are doing, and how the school is doing…The reality is that there is currently very little data in schools and what data does exist is summative data, which arrives too late to be useful, and has to be manipulated manually. We do not have the management systems that harvest a wide variety of learning outcome data automatically, can understand that data, and can analyse and represent that data in ways that allow teachers or third-party classroom management systems to make effective use of it. The sort of data-management capabilities that Oates is describing, the sort that we have in our schools at the moment, is the ed-tech equivalent of the Banda machine.
Conclusion
My initial reaction to Tim Oates’ video is “thank goodness—at last someone who is talking some sense”. I admit that this impression of general agreement may have been blunted by the various criticisms that I have made of Oates’ model on points of detail. Maybe these disagreements turn out to be of the same sort of order as the schism described by Monty Python between the Judea People’s Front and the People’s Front of Judea—or at least they may turn out to be the sort of disagreement that will be easily resolved by further discussion.
The main point that I want to draw out, however, is that while I share most of Tim Oates’ vision of what a well-organised education service, delivering good pedagogy and good assessment would look like; I do not think that Oates will be able to achieve such a vision without the sort of ed-tech that I have been trying to outline in this blog. Only with the assistance of ed-tech will Oates be able to deliver his vision at the sort of scale that modern education requires.

There was a lot to take in here but you voiced my key concern with Oates’ explanation when you said, “…the lack of meaning in criteria descriptors is at the root of most of our problems.” Oates does directly address your point about assessments exemplifying meaning in this document. http://www.cambridgeassessment.org.uk/images/112281-could-do-better-using-international-comparisons-to-refine-the-national-curriculum-in-england.pdf
Thanks Heather, both for the comment and for the reference, which I will have a look at (just cooling of on the platform at Ebbsfleet after a mad dash to catch the train). I recognise that there is a lot to take in here – I have been sitting on much of it for a couple of years as I know it will be hard to engage with – but t I believe it is important from the point of view of measuring learning, establishing what works and releasing the power of big data in education. I’ll comment again when I have looked at Oates ‘ comment. C
Pingback: Assessment after levels- In search of the holy grail…. | From the Sandpit....
I’ve just come across this and it occurred to me that you might be interested in (or appalled by) our new approach to assessing English in the UK secondary context. It goes for a standards-based approach and, if nothing else, has developed in our teachers a deep and genuine interest in the field of assessment. I’ve written about it here: http://chris.edutronic.net/unlock-achievement/ – and I’ll pass this item on to my team.
Hi Chris, Thanks very much for the link. I am certainly interested and am sure that this sort of innovative work is helpful. Much of what you are doing I thoroughly approve of. Some aspects I am a little cautious about.
I really like the fact that this is an assessment system driven by what I would call capability. I think the reaction against criterion referencing risks throwing the baby out with the bathwater in this respect.
I really like your use of “detailed exemplars to illustrate what “success” looks like” – my perception that learning objectives require this sort of exemplification is the main reason why I question Tim Oates language about “constructs” and the whole assumption that learning objectives can be described in short rubrics.
I really like your language when you talk about “moderating achievement with rigour” and the fact that “one of the most important lessons of all [is] the lesson taught by failure”.
I really like the idea of innovation in assessment schemes bubbling up from the bottom and not being imposed from the top.
But there are two problems I perceive in your initiative:
1. That it will not bubble up, but simply be used by yourselves, when it either duplicates the work of other teachers (surely we should centralise what can be centralised?) or simply becomes a more complex sort of lesson planning. There must be a mechanism for proving and sharing effective assessment schemes? In a way, it was a bit irresponsible of Michael Gove to say to teachers “go forth and innovate” without putting in place a way of ensuring that successful innovations could be replicated.
2. I suspect that the criterion by which you, as teachers, will judge the success of your scheme will relate only to the support you find it gives to teaching and learning, and not so much to its reliability as a means of assessment. Of course, the first is important – but so too is the second.
In this respect, I think the binary nature of your capability representations are problematic. From the motivational point of view, it is good I am sure to be able to say, “well done, you got the badge”. But from the assessment point of view (and recognising that there is always more to do), one needs to judge the degree of excellence in a performance – and that is generally requires a more complex sort of metric. Both types of assessment can be combined, of course – maybe with binary objectives being used at a more formative stage and graduated performance metrics being used towards the more summative end of the continuum.
If you were to extend the use of your model beyond your own school (which you would need to do if it were to serve a useful summative purpose), then your (I suspect informal) approach to moderation would need to develop to maintain consistent interpretation of your capability representations across different schools. And as soon as the achievement of those badges began to carry some weight, you would find grade inflation quickly beginning to creep in as teachers tried to do the best for their own students. In other words, the problem would become exponentially more challenging, even if, with strong exemplification of performance, I think you would have laid good foundations for managing such a challenge.
I am sure you will say that you are doing this for your own purpose and have no intention of becoming an exam board. But if you don’t cover the requirement for reliable summative assessment, will your work end up achieving any more than if you simply worked out your own programmes of study?
I think the idea of Mozilla open badges is a nice one – but I have always thought that they lacked a data-defined “back end”. How do you ensure meaning and consistency in what the badges say? And if you cannot do this, how do you guard against accumulating “badge junk” which savvy teenagers will surely regard with the same jaundiced eye as the gold stars that they worked for in key stage 1?
What I propose that data-driven edtech can do is to provide data formats that would allow you to express your learning objectives in a way that everyone (including software systems) could understand, allowing you to feed your assessment data into learning analytics systems which will demonstrate their reliability, their validity, and the significance of what you are measuring. The edtech would provide the tools that would make your schemes certifiable, providing joined up teaching and assessment and enabling innovation in assessment techniques and the sequencing of intermediate learning objectives.
But providing that sort of edtech is a significant undertaking and will only happen if government gets interested in what edtech could do.
Do let me know what you think of these comments. I would be interested to hear whether you have been facing any of these issues already. And I look forward to exploring your site and what you are doing in greater detail.
Best, Crispin.
Hi Crispin,
Thanks so much for your thoughtful and detailed response. It has been tremendously helpful. I agree with all the points you make, actually. At present we conceive of this process as an entirely internal one, so are focussing our energy on making sure that the ‘standards’ are securely understood and applied within our school community. This, as you say, is easily done in a small localised environment where the process and outcomes can be examined and discussed in detail. I’m not sure if I’m arguing for a summative role for these badges, as I am embedded in a system where summative outcomes are largely defined by monolithic exam boards. What we are exploring are means by which we can make our much broader and (let’s face it) more subjective school curriculum meaningful to the learners. For us, the process is about defining what is important in the learning in terms that the users (in our case, largely parents and students) can understand and interpret. It’s part of a wider objective that has as its focus a development of meaningful engagement by those parties – something that perhaps many schemes of assessment tend to sacrifice?
I do appreciate the potential issues with badges that you identify. This is how we’ve worked to mitigate these in our local environment:
1) It may not bubble up. I would agree that a scheme like this is ultimately a complex component of lesson planning, however I see this as a strength. The extent to which the teachers on our team have had to develop their understanding of assessment has been important professional development for them, and arguably has made them more effective teachers. My response to this is that the part that ought to ‘bubble up’ is the exhortation for teachers and schools to develop a system that is localised like this one for internal, departmental, assessment as this is the kind of work teachers do embrace. The part that could bubble up is the framework and standards-based approach – the system rather than the content.
2) Reliability. The system won’t be effective if the results aren’t reliable, so I don’t think we’ll find an unreliable system useful even if we can perceive collateral teaching and learning benefits from its use. However, in our subject we have often seen many of (what we regard to be) the important facets of our work sacrificed on the altar of reliability. Part of the motivation behind our developing this system has been in order to allow us to ascribe value to aspects of learning in our subject that the existing system – particularly the summative national assessment system – has not. This is particularly important in the English educational climate where the specifications for these national assessments have often become the default curriculum for many schools. This matter of reliability is currently being addressed via our (not really informal) moderation scheme. This document is an example of how the standards are tested and developed through a process of sampling and exemplification. We believe this system is a robust (samples are taken on a randomised basis) and effective means of ensuring reliability – and as you mention, educational technology could be introduced to allow for this process to ‘bubble up’ also.
3) Binary outcomes. We have developed a set of standards that increase in complexity. In a sense we’ve defined contexts and parameters for earlier badges to be more concrete and simplistic and the increasing complexity of future badges provide the opportunity for students to be credited for work that is more advanced. An example of this is the progression from presenting a poem by heart, through presenting a persuasive speech to performing a dramatic monologue. I do understand that each of these tasks has, also, a differing set of success criteria – however, there is always going to be room for the teacher, in the classroom context, to reward and acknowledge outstanding performance. Our conception of the standards we have set is that they don’t define mastery so much as important thresholds across which we want the majority of our students to pass. Their fixed nature allows for them to be understood and contested by all. To us, as mentioned earlier, this is a key feature.
We still operate, in parallel, a summative assessment process, via formal examinations, which we see as a natural accompaniment to the badges and which enable us to generate a more graduated set of data against which we can evaluate the results generated by the badges system. In this sense we do see the badges as a more formative assessment, with the examinations providing the more graduated summative results.
4) Does this offer more than if we worked out our own programmes of study? This is an interesting point as the badges also arose from our earlier innovation where teachers all devise their own programmes of study – and offer these to students each year as a selective process. We needed to develop a system for assessment that would both empower students to diversify what was taught as well as provide a robust tool for ensuring each programme met the subject learning needs of the students. I think a system like ours is a natural extension of our devising our own programmes of study – in the sense that we’re also devising our own means of assessment – but for me it also provides me with a very precise method of maintaining a clear and specific insight into the impact and effect of these variegated programmes that I would contend neither formal summative assessment (narrow scope) nor ‘levels-based’ classroom assessment (high subjectivity) have provided. Using this system – and without having to ask anyone – I can now see exactly which students in which classrooms have not yet written an accurate paragraph, have not yet spoken in a public forum etc. I find this information useful in a day-to-day sense, which is where most assessment information should be useful.
Remember that a badge system is incredibly easy to administer at a classroom level, which in turn allows for teachers to gather useful information on a much more granular level than in the past – but without resorting to having to devise multi-choice type probes all the time to elicit this information (and I’m not against the use of multi-choice testing by teachers in classrooms, I just contest that it’s not the most useful tool if you’re trying to encompass the complexities of learning outcomes in subjects like English or Drama).
5) Grade Inflation. Yes. I would imagine if this system were simply replicated across a system that would be the immediate effect. Even for that reason alone I am not arguing for it as a nationally-standardised summative tool, rather I’m proposing it as a way of thinking about school-based assessment that might have agency.
I’m in agreement with the potential for educational technology to provide for the establishment of a set of consistent standards across a system. Particularly if technology were implemented that allowed for the discussion of and exploration of ideas about ‘success’ in complex processes like writing and literary analysis. I think that in-school systems like ours go some way towards supporting this hypothetical future because the work is published and the standards are defined. It would make a lot of sense if a cluster of schools were looking to implement similar systems that reference standards and moderation procedures could be implemented that provided a greater degree of summative validity to a school’s internal assertions.
Again, thanks so much for taking the time to look at what we’re doing.
C
Hi Chris,
Thanks very much for your kind tweet and detailed comment. I think our respective interests represent opposite ends of a process that will ultimately join up. I am currently trying to get something going on ed-tech standards in W3C – you might be interested in a paper that I recently co-wrote here. The currency of any real standardisation work at this level is implementation (which is in the hands of the ed-tech suppliers) and use-cases (which is where your own practice may be on the button) – if we can get something going. As the paper mentions, there has been a long and not-entirely glorious history to this sort of thing.
I make the following comments without yet having studied your documents in more detail – I will come back again when I have done so.
I take your point about holding a balance between pedagogy and reliability. One of the benefits of constant monitoring is if the train you are tracking disappears from view for a while (from the point of view of reliability, if you can follow my tortured analogy) it doesn’t really matter because it will come back into view soon enough. The reliability of a hard-to-assess instructional sequence can be judged, maybe not intrinsically but certainly with respect to its consequential effect on other performances that are more amenable to assessment. Maybe the confidence-boost acquired by appearing in the school play might show up in the subsequent end-of-unit tests.
With regard to multiple-choice tests, I am sympathetic to Daisy Christodoulou’s recent argument that they have their use, particularly in ensuring that vital preparation has been covered before engaging on the more challenging creative exercise. She suggests that there is a strong correlation between well-designed multiple choice tests and full length essays – and they are quicker (and therefore cheaper) to mark, so may represent not a replacement of more qualitative assessment, but a net addition.
But I also agree with you that teacher judgements are critical for assessing softer (and generally, more interesting) objectives. The problem at the moment is that the data shows teacher judgements to be unreliable (so I am told by Amanda Spielman, the independently minded Chair of Ofqual), largely because of the conflict of interest that I have already mentioned. But this only becomes an issue when the judgements carry summative significance.
So I think that analytics systems could help by showing how reliable different teacher judgements were – not just so that you can discount teacher x as a rubbish assessor (though lets be straight, this is what you *would* do at a summative level) but because you could alert teacher x that their judgements were out of line. That provides the sort of systematic moderation system that will be important when this approach scales beyond the school and to the summative. The data-driven moderation system must be servant and not master to teacher- and ultimately community-defined learning objectives. So I agree with your comments regarding teacher control.
I keep going on about the summative because I believe that summative assessment is inevitably the ultimate master. However useful your badges are as a pedagogical tool, if they are not recognised formally, there will come a time in the course where you will have to put away your toys, as it were, and concentrate on whatever the formal assessment system requires.
In short, I am sure what you are doing is really useful from a pedagogical point of view. I hope that with the addition of (as yet, non-existent) ed-tech, it will be able to join up formative and summative assessment, ensuring summative assessment systems that are more reliable, more focused on more useful objectives, and more integrated with the teaching process. Its still quite a distant dream, to be honest. What you are doing is much more here-and-now. But it would be great to stay in touch.
Thanks very much again for your comments and, when I have some more time, I promise I will check through your online documentation again.
Best, Crispin.
Chris,
One further possible issue I have with the binary badge paradigm is that it encourages the award on first performance – you made breakfast over a camp fire so you get the badge, sort of thing. Often the first performance is heavily supported, with much recent drilling and scaffolding, and does not provide good evidence of a sustained capability to reproduce the performance in a wide variety of unexpected situations. Of course, robust criteria may deal with that problem – but I suspect it is a tendency of badge-based systems.
Similarly with the notion of “if you first don’t succeed, try, try again”. This makes good sense from many points of view – but it does suggest that you end up awarding the badge to someone who has failed to meet the performance criteria on 9 out of the last 10 attempts. Reliable assessment systems need to take a statistician’s perspective and look for repeat performances as a means of demonstrating the reliability of the assessment.
Crispin.
Hi again,
I see the potential for both of these limitations to exist in badge-based system. My main answer – as is probably the answer to most flaws in the implementation of assessment – is that effective use of badges is dependent on the competence and professionalism of the teachers administering them.
Badges don’t have to be the end-point of learning – and one problem area that a summative outcome prevents is the tendency for school curricular to repeat certain limited learning processes ad-infinitum.
Another factor that mitigates the concern about the need to demonstrate ‘repeat performance’ is the fact that our badges are devised with a degree of cross-over in their criteria. Students are therefore demonstrating certain capacities repeatedly in different contexts or at differing levels of sophistication. This could even be better than a standardised test repeated ad-infinitum as it mitigates against the tendency for teachers to teach ‘passing the test’ in preference to the core capacities the tests have been devised to assess.
Another important caveat is that our badges don’t define the mode of assessment. So a student’s literary analysis capacity can be demonstrated in spoken or written forms – this also means that across a rich array of classroom activities a student’s capacity is being evaluated, so in accompaniment with a diverse programme of learning, a student’s attainment of, say, the “This is Novel” badge is unlikely to be demonstrated on first try, nor only after multiple attempts at completing or refining the same task. The same is even more true of an achievement like Soliloquy (here’s an example of a student who did not achieve it – read the feedback the badge system enabled) – he cannot simply “do it again”, he has to go and work on it).
I think the “success on first attempt” and “If at first you don’t succeed” concerns are likely to apply more to badges where the criteria are so specific and quantifiable that a learner could literally construct their ‘answer’ by reverse-engineering the criteria (Come to think of it, this sounds a lot like how the GCSE assessment programme drives education in England at present!)
This has really helped me think things though, and helped me develop a better alertness to the pitfalls that will undoubtedly befall us as we develop this programme further. Thanks kindly,
Chris
Very glad to have happened upon this piece, Crispin. You’ve given it a valid analysis and the points you make are crucial. My concern is that there is no end of palliative rhetoric flying around at the moment and teachers, who naturally do what they’re told (in spite of the obvious evidence that it’s been so ‘wrong’ in the past), are unlikely to question such things as ‘making teacher assessment more reliable’. I particularly appreciate how you outline the assumptions about inconsistency between assessment methods and I am very concerned at the moment that we are being asked to carry out an impossible task – make reliable judgements without a yardstick at all. I also totally agree that embedded assessment and learning is the way to go but it seems to move further away the closer we get!
Hi Juliet, Many thanks for your comment and I’m pleased it was interesting. For my part, it is always useful to hear perceptions from teachers, as I have now left the classroom. I have been trying to make the argument that ed-tech will help this process – but it is hard to get through to decision makers, particularly when most people in the ed-tech world are interested in other things. Crispin.
Reblogged this on How do we know? and commented:
Covers everything I would want to say, only with more authority.