
 Most of our common assumptions about assessment are wrong, perpetuating the poorly performing system in which we are trapped
Most of our common assumptions about assessment are wrong, perpetuating the poorly performing system in which we are trapped
This essay is an extended version of the talk I gave at the Bryanston Education Summit, on 6 June 2018. I must admit that at nearly 15,000 words, it is no quick read. But I hope you will be prepared to take the time to look at it, first, because I think you will find many of the arguments that it contains to be original and perhaps surprising; and second, because I believe that in presenting a carefully argued case against many of our current orthodoxies about assessment, it suggests how we need to move in a radical new direction in our search for solutions to our current problems with assessment.
SLIDE 01

Introduction
Our prejudice against data
SLIDE 02

They say that data is the new oil. If you want to become rich, if you want to be a Rockefeller of the 21st century perhaps, then data is the business to be in. Data provides the battlefield for our twenty-first century wars (a sign of its strategic importance) and data is transforming the way that services are delivered in almost all sectors of or economy. Except in education, where it is commonly condemned as reductive and its use is generally resisted. Either education must be very different to other services; or educationalists do not understand data and the opportunities it offers them.
SLIDE 03

Warwick Mansell built the case against data in his 2007 book, Education by Numbers, the tyranny of testing in 2007. It explained how New Labour’s emphasis on assessment had:
- narrowed the curriculum,
- encouraged systematic cheating,
- undermined the confidence of many children by submitting them to constant failure.
I recognise all of these problems. But what Mansell succeeded in doing was in showing how bad our testing system was. The fact that something is done badly does not mean that it cannot be done well. It does not show that testing is necessarily a tyrant or that numbers are necessarily reductive.
Yet that is the conclusion that most teachers drew. And the same argument crops up in our educational discourse again and again: because we do something badly, we cannot expect ever to do it well. It is a sort of defeatism – a sign that, as a profession, teachers have lost hope of making any radical improvement.
The argument against performance
SLIDE 04

All data about learning is captured by assessment and assessment observes performance. Another argument that was pioneered by Warwick Mansell and has become almost universal since then, is that assessment-driven teaching fails to understand “the difference between ‘performance’ and ‘learning’” [Mansell: Assessment in schools, fit for purpose?].
Two arguments are commonly made.
One is from Carol Dweck, who has argued for a “learning” mindset rather than a “performance mindset” (and later a “growth” mindset rather than a “fixed” mindset). Yet when Dweck talks about mindset, she is telling us how to approach our performances: focusing on the matter in hand, not worrying what other people think of us, and believing in our ability to improve. She does not say that we should not elicit performance in our teaching and she does not say that performance is not a good guide to learning. She does say, writing recently in the TES, that her views have been widely misrepresented.
The second argument comes from Robert Bjork, who observes that “short-term performance is a bad indicator of long-term learning”. The fact that we can do something today does not mean that we will be able to do it on another day or in another context.
The argument ignores the fact that performance does not have to be short-term. We can (and indeed we should) elicit repeat performances over an extended period and in a variety of contexts. While teachers and educationalists often interpret Bjork’s work to be a criticism of eliciting performances, the opposite is in fact the case: Bjork argues that while repeated restudying benefits short-term performance, testing (i.e. eliciting performance) benefits long-term learning.
Neither of these arguments against what is pejoratively called “performativity” has any substance at all. Performance is not only a good guide to learning – it is our only guide to learning. We cannot cut open our students’ brains and check out what knowledge is inside. It is only through observing performance that we can infer these things.
If performance is the only way we can observe learning, then that is what we mean by learning. Talk about learning that cannot be related to an improvement in performance is, quite literally, meaningless.
Note. For the argument on why an inability to measure undermines meaning itself, see my Elephant in the Room
The argument against correlation
SLIDE 05

Another way in which educationalists express their distrust of data is by telling us that “correlation does not imply causation”. Correlation is, after all, the main thing that data is good for; and causation is the main thing that teachers are interested in – so if it is true that correlation does not apply causation, then data-analytics is probably not for us.
I frequently hear people in education say things like this. Norwegians live longer than other people and they also eat more reindeer meat than other people; and it would surely be simplistic, they say, to assume that one was the cause of the other on the basis of this correlation.
The fact that Norwegians live longer than other people is a single data-point. The fact that Norwegians eat reindeer meat is another single data-point. The coincidence of two single data points is not a correlation. The example is therefore not relevant to an argument about correlation.
SLIDE 06

So too is the coincidence of trend lines, like this one that you will find online. Basic trend lines go up, go down, stay flat, they peak or they bottom out. And two trend lines like these have only very slight perturbations, which make them very easy to fit together. This sort of pseudo-correlation is only slightly more statistically significant than the coincidence of two single data points.
SLIDE 07

This is what a serious correlation looks like. And where there is a correlation between large datasets with sizable and apparently unpredictable variations, it becomes extremely unlikely that this relationship is due to chance. If it is not chance, and if you believe that correlation does not imply causation, the onus is on you to explain what the nature of this relationship is. I have never heard anyone give me a satisfactory explanation.
SLIDE 08

When statisticians say that correlation does not imply causation, they mean to say that the fact that A is correlated with B does not show that A causes B. That is true and that is what they mean but it is not what they say.
SLIDE 09

The truth is that correlation does imply causation: a correlation between A and B implies either that A causes B or that B causes A or that a third variable, C, causes both A and B – or some combination of these alternatives – and all three of those possibilities involve causal relationships.
What is more, correlation is the only evidence we ever have for any causal relationship – read David Hume’s Enquiry Concerning Human Understanding if you don’t believe me. Hume points out that most people think that to demonstrate causality, you must be able to explain “what is going on”: you must be able to construct a model that shows how the billiard balls knock together or how the secret tendrils of causality join up. But that is a model: it is a picture we construct in our minds. It is not evidence. To show that our model is accurate is what we need evidence for. And the only evidence that we will ever have to justify our models of causality is based on correlations.
It is true that we must not jump to simplistic conclusions about causality – but it is also true that the only way that we can come to justified conclusions about causality is by accumulating and triangulating correlational evidence. Which is why data analytics is so powerful. And it is why teachers who dismiss the importance data on the grounds of any of these arguments only show that they do not understand what data analytics can do for them.
SLIDE 10

The data revolution is not touching us – not because data has nothing to offer us, but because we, teachers and educationalists, do not understand it – and because most of what is said in educational circles about data (and about the assessments from which that data is sourced) is wrong.
You might reply, “Well, maybe that’s because we don’t need data. Maybe we are just fine as we are”.
Managing the problem of scale
SLIDE 11

The trouble is, we all know perfectly well, we’re not.
We all know what good teaching looks like at small scale. A mid-nineteenth century American President described his ideal learning environment as “a log hut with only a simple bench, Mark Hopkins (who was a theologian of the time), Mark Hopkins on one end and I on the other”. It could be Socrates on the other end of the bench, or one of us, engaging our small group of pupils in responsive dialogue and inspiring them with the excitement of creativity, the experience of the sublime or the wonders of the universe.
But it’s rarely like that anymore, if ever it was. And the problem that overwhelms us – that has overwhelmed us ever since the introduction of comprehensive education – is the problem of scale.
It is very easy to rail against factory education. But what do you expect? We have 8 ½ million children in full time education. Some of my colleagues in the edtech community suggested that if you introduced them to YouTube or Facebook, students could get on with it themselves. But that didn’t work out very well. It appears that if children are to learn basic skills and attitudes, they need to be taught.
I want to suggest that teaching could be seen as having two domains.
The first is the affective domain. This is about relationships, role-modelling, values, and inspiration. It’s what many teachers come into teaching for.
The second domain is about logistics. We need to devise compelling activities or tasks for our students. We need to sequence those tasks, assess them, give feedback, track progress, offer remediation and reinforcement. This is not about chilling out and trusting to your intuition, it’s more like being an air traffic controller at Heathrow on a busy bank holiday weekend.
Reversing the controls
SLIDE 12

Sticking with the aeroplane analogy, this picture is from a 1952 David Lean film, Reversing the Controls. The premise of the film was that this is what happens when you break the sound barrier in a plane not designed for supersonic flight. If you want to bank right, suddenly you find you have to push the joystick left. Which clearly leads to dramas in the cockpit.
I want to suggest that something similar happens when we break the scale barrier in education.
At small scale, the logistical side of teaching can be handled intuitively, in the context of our individual relationships. “John, you seem to be having some problems with x, so let’s do some more practice on that today”. At small scale, you would hardly notice that you are managing a logistical problem at all.
But it becomes more difficult to manage those logistical demands (or indeed to maintain those relationships) when you are in front of a class of 30 children with another 30 children coming through the door in 10 minutes.
As we break the scale barrier, the logistical challenge becomes overwhelming, manifesting itself as excessive workload, a critical shortage of teachers in many subjects, a steady degrading of dialogue and feedback, as well as an erosion of all those one-to-one relationships that teachers value so highly.
At small scale, intuition and relationships come first. At large scale, you must start by managing the logistical challenge: the controls have reversed. It is a romantic fallacy to believe that we can continue to live like artisan craftsmen in an age of mass education.
In my recent essay in the TES, I have argued that it is only by developing data-driven digital technologies that we can manage the logistical challenge of good teaching at scale, thereby making space for the personal, affective side of teaching as well. If you accept my argument, then the data revolution has a great deal to offer us.
But as all data about learning is collected through some form of assessment, we first need to be comfortable, not just about data, but also about testing.
Note. For my arguments on the use of edtech to handle our problems of scale, see Troops don’t have to come up with their own battle strategy in the TES or Why curriculum matters on my blog.
Weighing your pig
SLIDE 13

If you search for “weighing pigs” on Google, you will get two sorts of result.
The first is by pig farmers, explaining when and how to weigh your pig and what equipment you will need to do it. The second is by teachers, explaining why weighing your pig is a pointless exercise because it doesn’t make it any fatter. For teachers, weighing your pig is an analogy for testing your students, and its purpose is to suggest that testing is a pointless exercise.
It is a conclusion that is not borne out by the practice of pig farmers, who weigh their pigs regularly to find out if they are putting on enough weight, to check they are not putting on too much fat, to regulate the amount and type of food they are giving them and to decide when to book them in for slaughter (it is not an analogy that we should take too literally).
Teachers should understand the reasoning of pig farmers very well, because it is a direct analogy for Assessment for Learning. Because students learn so little of what we teach them, we need to use what is misleadingly called formative assessment to check what they have learnt, modifying our teaching to address any misconceptions and to progress only when they are ready.
In this respect, pig farmers and teachers find themselves in an analogous relationship. What the analogy shows is that testing and weighing, far from being pointless, are both very useful in allowing teachers and pig farmers respectively to adapt their actions appropriately.
In another respect, weighing pigs is a poor analogy for assessment in education because while it is true that weighing a pig doesn’t make it any fatter, it is not true that testing a student does not improve the student’s knowledge. Unlike pigs, students do put on weight, simply by standing on the scales. In fact, testing is one of the most effective ways that there is of teaching: it is called the testing effect.
Our minds are not like attics
SLIDE 14

Introduction
The reason why we learn by testing is that our minds are not like attics.
If you want to put things into the attic, you have to carry them up the loft ladder.
If you want to check what is in the attic, you have to retrieve all those things again, carrying them down the loft ladder again. As carrying things down the loft ladder clearly empties your attic, in the attic model, testing represents – at best – time-out from learning.
But our minds don’t work like that.
Putting information into your memory, by listening to a lecture for example, only puts that information into your short term-memory. That is why Robert Bjork argues that lecturing and reading only improve short-term performance. It is because information in short-term memory is soon forgotten.
Knowledge moves from short-term memory into long-term memory not when you put it in but when you take it out. Every time you retrieve a memory, the stronger that memory becomes. The more you get down from your mental attic, the more your attic fills up. And the more your attic fills up, the more space there is in your attic.
The reason our minds work like this is because they are not a repository of things but of associations.
Knowledge is a network
SLIDE 15

To the extent that our memory is a collection of things, we could say that it is a collection of concepts. Words, perhaps – words like “grass”. But a single word doesn’t tell us anything. It isn’t even a simple fact. Our first fact about grass comes when we associate “grass” with “green”. The fact is not stored as a thing but as an association.
SLIDE 16

To develop what we might describe as an “understanding” of a concept, we need a whole network of associations. Cows eat grass. Grass cut short makes a lawn. The smell of grass reminds us of summer afternoons watching cricket. These wider networks of associations draw in emotional reactions, behaviours and skills.
How varied practice develops understanding
These associations, which are the real stuff of memory, are created in the course of retrieving information – that is, in the course of testing.
SLIDE 17

Every time we retrieve the information “grass”, we do it in response to a prompt. And each time we retrieve grass in response to the prompt “green”, we re-enforce the association between those two concepts.
SLIDE 18

In order to develop a rich network of associations, we need to apply our knowledge in a wide variety of different contexts. And it is by the process of varied application of knowledge (i.e. testing) that we develop understanding.
What this means for teaching
SLIDE 19

Because knowledge is about associations, not things, learning is not about memorising facts but applying them. Another way of thinking about this process from an introspective point of view is in terms of emotional engagement: it is only when we use a piece of factual information that it starts to matter to us.
As these associations link factual knowledge, emotions and skills, so we should be wary of privileging one sort of knowledge, such as factual knowledge, over others – they are all inextricably intertwined.
We develop our associative networks primarily by retrieving and applying information. And the more difficult and varied that retrieval, the more effective it will be as a means of re-enforcing memory and developing understanding. Testing is not a distraction: it is the very stuff of teaching.
Why test? Why not just practice?
You might say that all we need is practice and there is no need to call it a test.
SLIDE 20

Practice involves producing a performance in response to a task which has been assigned to you. I say “assigned”, which suggests a teacher-controlled process but maybe the task was chosen by the student or recommended by a peer or by an automatic sequencing engine. What I mean is that, in one way or another, the task and the performer must encounter one another for a performance to be produced.
Teachers use many of these terms loosely. They will often refer to a task as an assignment, when, if it is used precisely, “assignment” refers to the process of allocating a task to a student and not to the task itself.
For useful practice to occur, it is not enough just to throw off a performance with your eyes closed: you also need to receive and respond to some sort of feedback. That is easy when the task is a physical one, like riding a bicycle, because you will then receive intrinsic feedback, just by virtue of producing a performance, from the physical environment. The bicycle itself will give you a lot of information about whether you are doing it right – and part of the skill of riding the bicycle lies in your ability to interpret that intrinsic feedback.
SLIDE 21

As students tackle more abstract tasks, like constructing an argument in a history essay, that intrinsic feedback is much more difficult to access and interpret, and so we become more dependent on what you might call extrinsic feedback, maybe from an expert teacher. I have elsewhere proposed a total of nine different sorts of feedback, but broadly speaking, one sort of extrinsic feedback consists of explicit comment, criticism or evaluation from the teacher, and another sort, what I call adaptive feedback, consists in the teacher calibrating or selecting the next task, according to the student’s performance on the previous task. Both these forms of feedback depend on an intermediate stage of assessment. The fact that the teacher has assessed the student’s performance does not mean that the teacher knows what to do about the fact that the student is getting it wrong. But if the teacher has not assessed the student’s performance, she will not even know that the student is getting it wrong, let alone why.
Just like “assignment”, teachers often use the term “assessment” inaccurately to refer to the task as “an assessment”, rather than to the process of assessing the performance on a task which might be primarily intended to offer practice. This gives the misleading impression that an assessment is somehow different from a practice exercise, when it is all part of a single process with different stages.
From the teaching and learning perspective, the difference between practice and testing is very slight. They both involve a task, an assignment and a performance. Effective practice requires feedback and for much of the time, this will also require some sort of assessment. The process of assessment does not take any extra student time and, if it is automated, it will not take any extra teacher time either.
Section summary
SLIDE 22

Because our mind is not like an attic, it is not true in an educational context that you don’t fatten your pig by weighing it. Practicing the retrieval of information in varied contexts is one of the best ways that we have of developing understanding and mastering skills. And because assessment is often a prerequisite for feedback, and because it takes no student time and may take no teacher time either, there is little practical difference between testing and practice and, it appears, little reason in principle, not to assess what the student does all the time.
Perhaps the only difference between practice and assessment lies in what happens to the assessment data that is collected: is it recorded or is it thrown away? And if it is recorded, is it useful?
Garbage in, garbage out?
Introduction
SLIDE 23

There is a common perception that much of our assessment data is neither valid nor reliable. And in that case, it is not going to be very useful. “Garbage in, garbage out”, as the popular saying goes.
In a recent webinar, Dylan Wiliam argues that a test cannot be valid, and it will almost certainly not be reliable either. Before I address Dylan’s arguments, let me run through the traditional meanings of these terms.
Valid and reliable
SLIDE 24

Reliability is about the consistency of data: it is the extent to which, if you run the same test, you will get the same result. Validity, according to its established definition, is about whether the test measures what it purports to measure. Many people take this definition further than this and say that validity is not just about whether a test measures what it purports to measure but whether what it purports to measure is what it ought to be measuring. As Dylan rightly points out in his webinar, many debates that appear to be about assessment are in fact about the legitimacy of the constructs that are being assessed.
Reliability and validity are often seen as antagonistic. Test designers who want to achieve high reliability abandon the attempt to measure those things that are difficult to measure and so validity is reduced. Test designers who want to measure those things that are important for validity but which are difficult to measure have to accept low reliability.
SLIDE 25

Even if reliability and validity often seem to be antagonistic, it is desirable to create tests which are, as far as possible, both reliable and valid. So it is useful to have a term that subsumes both qualities. The EPPI-Centre’s 2004 review of teacher assessment called this synthesis of both qualities “dependability”.
These different terms can be illustrated by the analogy of a shooting target
The shooting analogy
SLIDE 26
 The shots in the first case are reliable, because they are closely grouped, so they are consistent, but they are not valid in the sense of being aligned, because they are not on target. Note that reliable doesn’t mean accurate. It is quite possible to be reliably wrong – and this sets a trap for people who use the term “reliable” without understanding it in its precise, technical sense.
The shots in the first case are reliable, because they are closely grouped, so they are consistent, but they are not valid in the sense of being aligned, because they are not on target. Note that reliable doesn’t mean accurate. It is quite possible to be reliably wrong – and this sets a trap for people who use the term “reliable” without understanding it in its precise, technical sense.
SLIDE 27

In the second case, the shooter is aiming in the right direction and there is no systematic fault with the sights, but the shots are not consistent. One might say that this image represents validity without reliability. Some people disagree that this case is valid, because many of the individual shots are way off target, and how can you call an assessment aligned when it produces results that are not aligned? I will come back to this point.
SLIDE 28
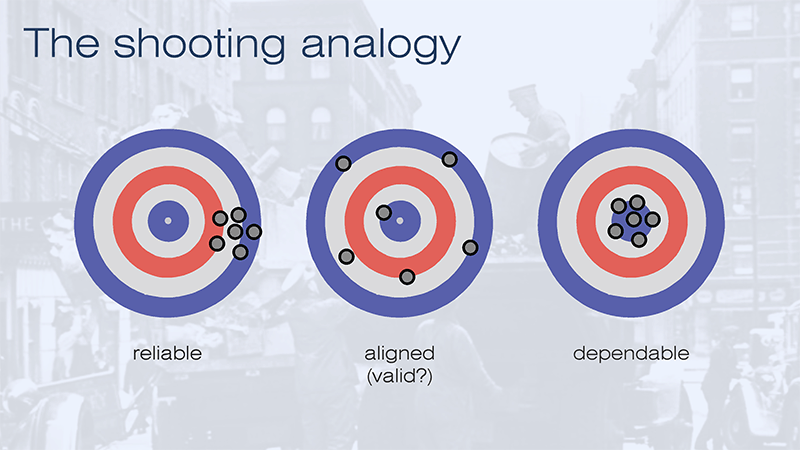
In the third case, the shots are dependable: they are both valid and reliable, in the sense that they are aligned and consistent.
There are at least three problems with the shooting analogy.
SLIDE 29

First, we are not trying to align to a single point, to a bullseye, but to a domain, or an area. This is what psychologists call the construct – or perhaps more realistically, a set of constructs. These are the things that we are trying to test, the things that we want our students to know or to be able to do.
Making sure that your test is aligned to the whole domain is more like trying to colour in a set of defined areas, rather than trying to hit a single point. And because our colouring-in is often not very good…
SLIDE 30

…there will be parts of the construct that our test does not address (this is called construct under-representation) and areas that our test addresses which are not part of the construct (construct-irrelevant variance), both of which reduce the validity of the test in the sense of being aligned with the construct or domain.
The second problem with the target analogy is that it conflates three different sorts of alignment. And this can be illustrated with a short story.
SLIDE 31

The target represents a legitimate construct. The test designer tries to create a test that aligns to the construct, in the sense that someone who gets full marks on the test can be inferred to have mastered the construct. I show this attempt at achieving alignment by sticking a pin in the target. Because achieving this sort of alignment is very difficult, we might assume that the test designer has poor sight and is not very coordinated, and generally puts the pin in in slightly the wrong place.
SLIDE 32

And then we tell the students to attempt the task and to align their efforts as closely as possible to our expectations of a really good performance. So here is a ladybird, representing the student, trying to find the pin, which represents full marks on the test. But most students don’t get full marks and so the ladybird generally doesn’t manage to get to the pin.
SLIDE 33

And then, to remind ourselves that we are on a rifle range, we try and shoot the ladybird. That is, we assess the student’s performance and try to align the observed scores that are returned by our assessment with the true score of the student.
The target analogy is rolling all three of these types of alignment into one – the alignment of the pin to the target, of the ladybird with the pin, and the shots with the ladybird. This is fine so long as we bear it in mind when we consider the analogy.
SLIDE 34

It means that we need to remember that these shots could be off-target because the test is poorly aligned with the construct, because the student has performed poorly on the test, or because there is systematic measurement error – or bias – in our observed scores.
SLIDE 35

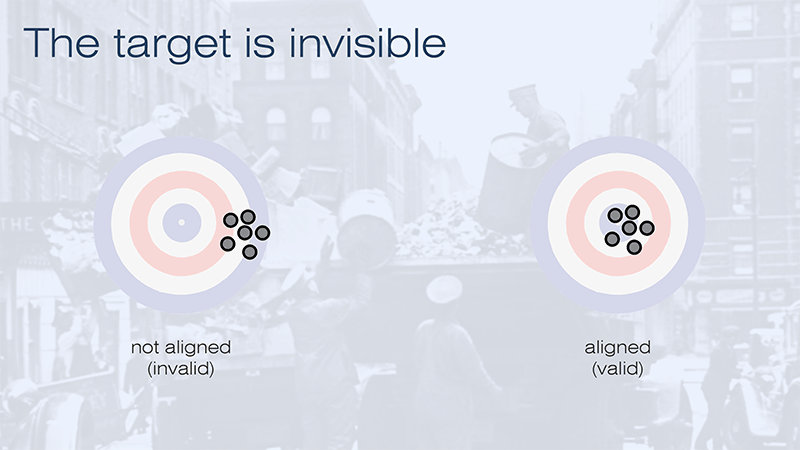
The third problem with the analogy is more serious. It is that while shooting is an exercise in trying to hit the target, assessment is an exercise in trying to find out where the target is.
Whether the target represents the construct or the student’s true score, we can’t see it. If we can’t see the target, we can’t judge whether anything is aligned with it. In practice, the aligned grouping and the unaligned grouping appear to us to be exactly the same. And if you can never show whether something is valid, in the sense of being aligned, then maybe validity is meaningless. This is a second problem that I will come back to.
Dylan Wiliam’s argument on validity
SLIDE 36

Lets move on to what Dylan Wiliam says about this. Dylan says that there is no such thing as a valid test because validity (which he uses as a synonym for “warranted”, not “aligned”) is not a property of tests. He says that calling a test “valid” is therefore a category error. What is warranted is not the test but the inferences that we draw from the test – and inferences are drawn by people because tests do not in themselves purport to test anything. That means that there is no such thing as a biased test either: Dylan sums up this view by saying that a test tests what a test tests and it is a person, looking at the outcomes of the test and making an inference about the student’s capabilities, who is doing the purporting.
Meaning of “validity”
SLIDE 37

The OED offers three definitions of “valid”. First, it is used of an assertion that has a sound basis in fact or logic. If we assume that all men are mortal and Socrates is a man, it is logically valid to conclude that Socrates is mortal.
A legal argument or contract can be valid in a similar way if it has a sound basis in law.
And a legal instrument, like a passport, can be valid if it is compliant with the requirements for passports, i.e. that it is properly signed, is in date, and you are not smiling too much in the photograph.
SLIDE 38

Pulling these three definitions together, we can see that the general sense of “valid” is not the same as “warranted”, as Dylan claims it to be. It is not about whether something is true or justified, but about whether it is acceptable because it is compliant with the rules.
If a passport can be valid or invalid, then it is not a category error to describe a test as valid or invalid, so long as we can define a set of rules with which the test needs to comply. And although we are very bad a defining our constructs, it is perfectly plausible to imagine that we might one day define our constructs clearly. And maybe we could even devise a way of demonstrating that our test was aligned with that construct, in spite of our difficulty with the invisible target – and in those circumstances, we could create a set of rules which required valid tests to be aligned with legitimate objectives.
Valid also has the sense of being a binary property: either a passport is in date or it isn’t; either a deduction conforms to the rules of logic or it does not.
Thirdly, it generally has a sense of pre-qualification. Just because you have a valid passport does not mean that you are going to be allowed into North Korea; just because you submit a valid job application doesn’t mean you will get hired. Just because a test is valid, in the sense of being aligned with its target, doesn’t mean that it is going to give you reliable data.
Meaning of “inference”
SLIDE 39
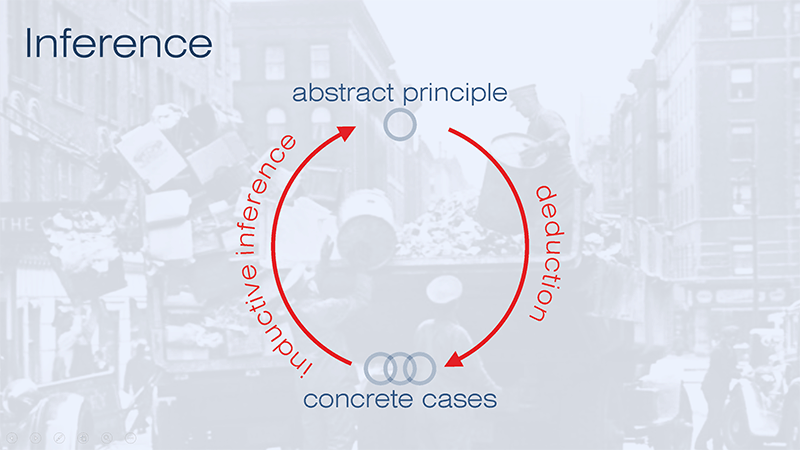
If Dylan thinks that what is valid or invalid are our inferences, it is well to be clear about what we mean by “inference” as well. Most of the time, people use the term to mean the opposite of deduction. Strictly speaking, this is not accurate. The opposite of deduction is induction and both deduction and induction are forms of inference. But in practice, inference is normally used to refer to inductive inferences, and that is true in the case of assessment.
Deduction is the logical process whereby we start with abstract principles and apply them to a particular case, like predicting that Socrates will in fact die because of the abstract principles that all men are mortal and Socrates is a man.
Inductive inference is the opposite of a deduction. It starts with a concrete case and ends up with an abstract principle. We observe Socrates drinking the hemlock and conclude that all men are mortal. That would of course be premature. We would have to observe thousands of people dying from hundreds of different causes before we had any reason to presume that all men were mortal; and even then, we could never be sure.
The process of deduction is binary. So long as your premises are true, you are either following the rules of logic or you are not. But inductive inference is probabilistic – it is always a different shade of grey.
Because validity is also a binary property, it is appropriate to questions of logic but it is not a property of inferences.
While talking of valid tests is not a category error, talking of valid inductive inferences is a category error. Dylan has got it the wrong way round.
“The test tests what the test tests”
The second problem with Dylan’s argument is his assumption that tests do not purport to show anything.
Imagine you go to the doctor and say “Doctor doctor, I am getting very forgetful. I am worried I am getting Alzheimer’s.” And the doctor says, “Well, we’ll have to give you a test. Here – go and pee on this stick”. And you say “Doctor, that’s not an Alzheimer’s test – that’s a pregnancy test”. And the doctor says, “Well, you shouldn’t worry about that. A test tests what a test tests. What really matters is what inferences I choose to draw from it”.
Some tests require human raters to interpret – but many don’t. I am told that a pregnancy test is pretty easy to interpret. And even where judgement is required, that judgement is generally exercised within constraints established by the test designer, and the sort of inferences that can be drawn are limited by the sort of evidence that the test produces.
There is no such thing as a generic test: all tests have a purpose; all tests purport to test something. There are Alzhiemers tests and pregnancy tests; intelligence tests and lateral thinking tests; tests of agility and tests of reading-comprehension.
Inferences should be supported by evidence. And the most useful sort of evidence in most circumstances is not a copy of the student’s exam script or a video of them on their geography field trip. These may be necessary as evidence of the last resort but they are labour-intensive to process and are subject to interpretation. Where there is a human rater involved, what is much more useful is to know who that rater is and how dependable their judgments generally are. Whether or not there is a human rater involved, it is useful to know the identity of the test on which the inference was based and the dependability of that test. If your friend tells you she’s pregnant, ask her whether she used the test kit from Boots or whether she’s been looking at the tea leaves again. The provenance of the test and, if appropriate, the rater, are some of the most important pieces of evidence that we can have. And that is only true because it is the test (sometimes but not always in combination with a rater) that is doing the purporting.
SLIDE 40

Another problem with Dylan’s assertion that validity is a property of inferences is that to say that an inference is valid, in the sense of being aligned with what it purports to measure, is a tautology, which is way of saying it is meaningless.
We are dealing with a process in which the student is assessed, producing a score, and on the basis of that score we make an inference about the student’s mastery of a construct. In that 4-stage process, the score references the test. If you want to understand the meaning of “8 out of 10”, you need to know that it is “8 out of 10 in the weekly maths test”. The inference references the construct: if you want to understand the meaning of “mastered” you need to know that this inference states “mastered simultaneous equations”. So you can see that the inference that the student has mastered simultaneous equations must by definition be aligned with being good at simultaneous definitions.
SLIDE 41

The only question of alignment comes between the test and the test scores on one side and the construct and the inference on the other. Although the inference cannot be out of alignment with the construct that it references, it is quite possible that getting 8 out of 10 on the weekly maths test does not in fact show that you are good at simultaneous equations. The question of alignment arises in the case of the test but not in the case of the inference.
Summary: why Dylan is wrong on validity
SLIDE 42

So the first problem with Dylan’s argument is that it is not a category error to describe a test as valid.
The second is that it is a category error to describe an inference as valid.
The third problem is that he is wrong to suggest that tests do not purport to show things. Tests tend to be rules-based systems for making inferences. Even tests that require human judgement to interpret will constrain the sorts of judgments that human rater can make.
In a Twitter conversation on this point, Dylan accepts my argument about purpose when applied to medicine but replies that this is not how things are done in education, where teachers commonly use tests for purposes for which they are not designed and for which they are not suitable. This is another variety of the “because we do it badly, we can’t do it well” fallacy. It is of no consequence if teachers commonly do the wrong thing.
You might say that some of these arguments are a case of tilting at windmills. I am saying that it makes no sense to say that an inference is aligned to its construct, when Dylan is using the word “valid” to mean “warranted”, not “aligned”.
While this might be true, it also highlights why it is undesirable to change the definition of terms. First, because changing the meaning of a term does not say anything about the real world, only about your definitions. It appears, when Dylan says that there is no such thing as a valid test, that he is saying something about tests; when in reality he is only saying something about how we define “valid”. Second, changing the meaning of terminology merely confuses people, because some will continue to use “valid” to mean “aligned” while others will use it to mean “warranted” and no-one will understand what anyone else is saying. In fact, I think that Dylan himself continues to use “valid” to mean “aligned” in some contexts and not in others.
You might also accuse me of being rather pedantic, in picking up all these semantic and epistemological arguments, when what is really of interest is what effect this is going to have on education. Why does this argument about validity matters at all; what is it all about?
The answer to that question is a matter of interpretation. It seems to me that when Dylan says that validity is not a property of the test but of the inference, and that inferences are made by the people on the spot and not by replicable tests, the effect of this statement is to create a perception that undermines the legitimacy of the test in favour of the professional judgement of the teacher. It places the emphasis on the human rater. This is a popular message with teachers, who I think have mistaken their true interest in this matter by seeing formal testing as a threat to their autonomy and professionalism.
Although I think human raters are really important, they suffer from two serious problems: first, they tend to be unreliable; second, they are expensive (which means the volume of assessment data we can acquire through human raters is low). For both these reasons, I think we should be using human raters as little as possible. Where we can automate an assessment, we should do – both for the sake of saving money (which means doing more testing) and for the sake of improving reliability. The practical effect of Dylan’s doctrine that the test itself cannot be valid therefore points, I believe, in precisely the wrong direction, if we are to create plausible solutions to the problem of scale.
Before I leave the topic of validity, there is one important argument that Dylan uses to support his position to which I need to respond. He observes that a test might be valid for some students and not for others and that therefore we cannot describe the test as either valid or invalid in a general sense. He gives the example of a Maths test that requires good reading ability to understand the questions: it may accurately assess the maths ability of students that are also good at reading but will not assess the maths ability of students who cannot read well, even though their maths ability might be just as good.
I accept that this argument has some merit. Plato argued that truth is permanent: either something is true or it is not, but it cannot be true one day and false the next.
SLIDE 43

Plato’s position might be brought up to date by considering how we might design a database. I might create a table of information about people: first name, last name, date of birth etc. – none of this information would ever change. If I added a field to say whether or not a person was happy, that field would constantly need to be overwritten: I might be happy today and sad tomorrow. Most data scientists would regard this as problematic (not least because you are constantly losing data) and would therefore create a second table, maybe called mood.
SLIDE 44

Here they could say that on 6th June, person 123 was happy, but on 7th June, person 123 was sad. And Dylan would observe, quite fairly, that in this case, happiness is not the property of a person but a property of a person’s mood.
I have four responses to this argument.
First, although I accept that “valid” (meaning aligned with its construct) is not a property of a test in a technical sense, nor do I accept that it is a property of the inferences that we make. It is in fact a property of the assignment…
SLIDE 45

…in the technical sense of that word that we discussed a moment ago. If we assign a Maths test with a demanding reading component to a set of students who cannot read, we know that it is an invalid assignment, from the perspective of measuring maths ability, even before any of the students has produced any performance or any inferences have been drawn.
Second, because teachers do not generally discriminate between the task, the assignment and the assessment (and you could argue that all these are aspects of a test), it is not going have an important impact on the way teachers talk about validity to say that it is a property of the assignment and not of the test.
SLIDE 46
Third, we have already observed that validity is difficult (perhaps impossible) to measure technically because we cannot observe the construct with which the test is to be aligned. I will come back to this problem again – but the consequence in the context of this discussion is that validity is also not a technical term but one that refers to an intuitive judgement. We might look at a test and consider our understanding of the construct and think to ourselves, “I guess they kind of line up”. And if we use the term “validity” in that non-technical, everyday sense, then I think it is perfectly acceptable, also using language in a non-technical, everyday sense, to say that a test is valid for one group of students and invalid for another group of students, just as we might say that I am happy on Monday and sad on Tuesday.
Fourth, if you accept my interpretation of Dylan’s overall, ideological position in this argument, which is that he wishes to argue that assessment depends principally on the judgement of the human teacher and not on the systematic sausage machine, then again, saying that validity is the property of the assignment does not help Dylan’s position, because data-driven learning management systems ought to be particularly good – and much better than the human teacher – at matching the right task to the right student, depending on the characteristics of the task, the capabilities of the student and the nature of the learning objective. This is in fact another strong argument for the use of digital management systems in education and against an over-reliance on human intuition, which cannot cope with this sort of logistical demand at scale.
Dylan’s argument on reliability
SLIDE 47

Dylan’s argument on reliability is different. He doesn’t say that a test cannot be reliable but that in practice, it almost never is. Even tests with levels of reliability that would generally be regarded as acceptable mean that in a set of 25 students, one student would have marks that are more than 12% out, and you will never know which student it is and whether they got 12% too much or 12% too little.
Before I proceed to the main argument, I will pick up one point, which is that in saying that you will never know which student was awarded entirely the wrong result, you are assuming that you will never corroborate this test result with any other. If you test repeatedly, as you should, any outliers will quickly become visible.
Nevertheless, the central point that reliability levels are generally too low to be very useful still stands. Before moving on to to discuss this point, let me describe what reliability is.
Deviation and variance
SLIDE 48
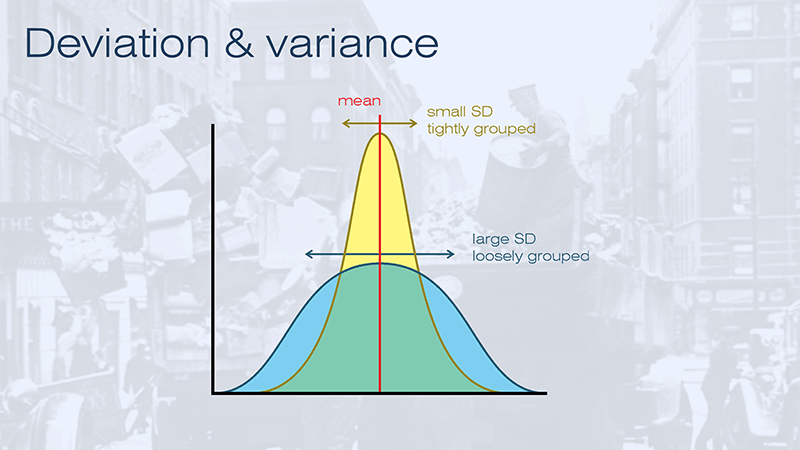
Reliability is a sort of deviation or variance, which measures the spread of a set of marks.
In this case, the yellow dataset has a small standard deviation, so the marks are tightly grouped around the mean; and the blue dataset has a large standard deviation, so the marks are more widely dispersed.
SLIDE 49

To work out the standard deviation of a set of marks, you start by working out the mean.
Then you subtract the mean from all the individual marks to find out the deviation of each mark from the mean. If you averaged those deviations, you would always get 0, because some of the deviations are positive and some are negative.
To avoid this problem, you square all the deviations, giving you a positive number in every case. The average of the squared deviations is called the variance and the square root of the variance is the standard deviation. This tells you in this case, given a normal distribution, two thirds of your marks fall within + or – 15 marks of the mean.
You can also add together all your squared deviations to get the sum of squares, which is what is used to work out Cronbach’s Alpha, which is the most common measure of reliability.
Cronbach’s Alpha
SLIDE 50

To work out Cronbach’s Alpha you need a table of results, here of 10 students taking 5 instances of the same test. You take the mean of each row to give you the mean score for each student, which is effectively your best estimate of the student’s true score. You then calculate the sum of squares for those mean student scores, which shows you the extent of variation between your different students, the extent to which you are looking at a mixed-ability teaching set, perhaps.
You do the same for the different tests, which shows you the extent of variation in the difficulty of the tests. Given that all the tests are supposed to be measuring the same thing, any variation in the difficulty of individual tests is a kind of error.
In this case, the difficulty of the tests is pretty consistent but the ability range of the students is widely dispersed, which means that our measure of reliability is going to be pretty high.
You then work out the sum of squares for all the individual results in the table. To simplify the next bit of the process, the error is the sum of squares for all the results minus the sum of squares for the mean student scores minus the sum of squares for the mean test scores. Cronbach’s Alpha expresses this error as a proportion of the variance between your students – the variance between the students not being error, but a reflection of reality. Some students are better than others. The more of the variance in the dataset that is due to the variance between students, the less of that variance can be attributed to error, and the more reliable the test will be.
SLIDE 51

From this, I want to draw a few conclusions.
First, not all deviation is error, which is not the pronouncement of a liberalising pope. It means that to assess reliability, we need to distinguish between legitimate deviation and error. This may not always be easy.
Second, reliability might be thought of as the property of a single test instrument, but strictly speaking, it is revealed by an examination of the test’s scores. You need a multiplicity of scores in order to discover the extent of consistency. A single thing cannot be said to be consistent, only that it produces consistent scores.
Thirdly, that data needs to represent the repetition of a single event over at least two dimensions – in our case, across multiple students and across multiple test instances.
What is represented in the second dimension can change.
Types of reliability
There are commonly thought to be four types of reliability, which are distinguished by what you are changing in the second dimension of our dataset.
SLIDE 52

Where a human rater is involved, you could test the reliability of a single test instance when assessed by different raters. Where human judgement is involved, the degree of error is likely to be high and I put that case in the right-hand “people” side of the diagram because, as Douglas Adams puts it in the Hitchhikers Guide to the Galaxy: people are a problem – at least from the perspective of achieving reliability.
On the right-hand side of the diagram, the most obvious case of system reliability is test-retest, when you use multiple instances of the same test instrument. Keep on handing out the same test and check that you get the same results. The problem with this is first, that student scores are liable to improve as they become more familiar with the test instrument; second, they are likely to get bored of doing the same test all the time; and thirdly, you are failing to vary the context of your assessment, which is what we have established is needed to build and to assess understanding.
SLIDE 53

Quite often, we have a single test instance – a summative exam perhaps – and we want to test the reliability of just that single thing. On the face of it, this is not possible. As we have already established, reliability is the property of a set of scores spread across two dimensions and not of a single thing.
Some people suggest that it can be done by testing the consistency of the individual items within that test. Do you get the same marks for questions 10, 11 and 12 as you did for questions 1, 2 and 3?
SLIDE 54

The problem with this is that the different test items will not necessarily purport to test the same thing. They may be testing a variety of different sub-constructs and the extent to which different items represent repeated attempts to test the same thing may not be clear. The distinction between repetition and coverage may not be clear either.
SLIDE 55

To return to the oil analogy – if you fancy your chances of finding oil in your back garden, you need to get your hands on a vibrator truck. Switch it on and surround it by a wide array of sensors, which can pick up the vibrations as they are reflected off whatever geological feature oil prospectors regard as propitious.
Just as the geological feature is deep underground, so the construct we are testing is an abstract property, deep within our minds. Just as the oil prospector needs to spread out the sensors over a wide area in order to detect that single geological feature, so the assessor needs to test the student’s capabilities in a wide variety of contexts, and preferably on different occasions, to assess a single construct.
SLIDE 56

Another analogy might be a traditional navigator, before GPS, who would fix the position of a ship by taking three different bearings of three different landmarks. Each bearing is different, so we are not getting identical data back from our different bearings. But the bearings are consistent in the sense that they all point to the boat being in the same position.
Consistency is a more complex concept than just repeatability. Only if each assessment item were collecting the same data could the reliability of items be taken as a good indication of the reliability of the test. And as this is unlikely to be true, I suggest that internal reliability is a problematic concept, which should be avoided.
SLIDE 57
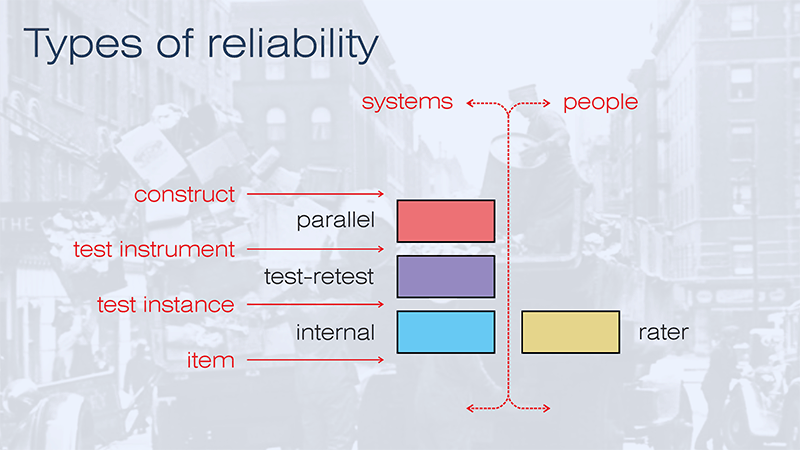
More promising is the fourth sort of reliability: parallel reliability, where you test the consistency of different test instruments, all of which purport to test the same construct. In this case, you are not testing the repeatability of the scores but the repeatability of the inferences. This is much more promising because it allows for the variation of context and methodology that we need if we are to get a rounded picture of the student’s capability.
The problem here is that in our education system, we have very poorly defined constructs. So this would be desirable but is rarely possible. Although there are rich forms of reliability that we could assess at the top of this diagram, our failure to use data analytics or to define our educational objectives means that we are constantly forced down to the bottom end of the reliability diagram, where the measure of reliability is superficial at best, bogus at worst, and is again tied to individual test instruments.
Resolving the validity conundrum
SLIDE 58

At this point I am going to switch back to the question of validity to address this loose thread which is still hanging unresolved. How can we establish validity, in the sense of being aligned with the construct, if we cannot observe that construct directly? In the analogy of the rifle range, how do we tell the difference between two closely grouped patterns of shots, when one is on target and the other is off-target, if we cannot see the target?
SLIDE 59
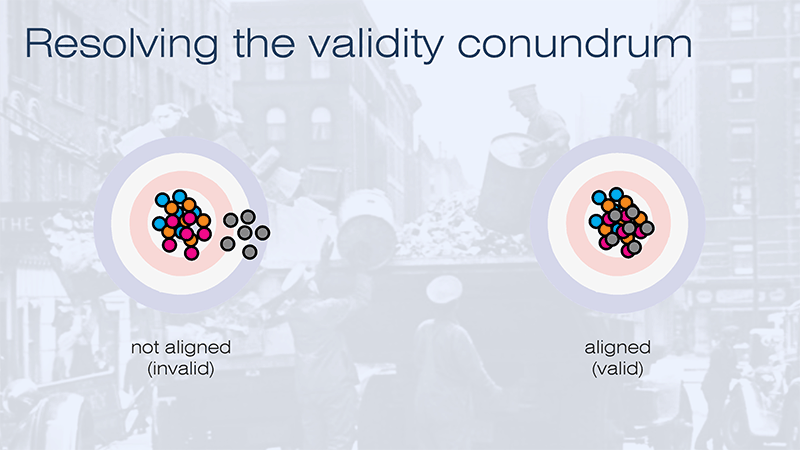
The answer is by parallel reliability. If the closely grouped pattern of shots is an analogy for the inferences produced by a single test instrument – or perhaps a single human rater – then we can compare the inferences produced by one test instrument or rater with those produced by other test instruments or raters. Unless everyone is off-target, in which case you would have to say that we simply do not understand what the construct means, then invalid tests (in the sense of tests that are not measuring what they purport to measure) will appear as outliers. And if we find that the inferences produced by a test instrument that purports to measure construct X are in fact more consistent with other test instruments that purport to measure construct Y, we will be justified in concluding that the test in fact measures construct Y and not construct X (which it purports to measure) at all.
It therefore appears that the most useful form of reliability – parallel reliability – is not only a measure of reliability but of validity as well.
SLIDE 60

Having discovered the importance of parallel reliability, I want to propose a fifth type: inter-construct reliability.
SLIDE 61

In his webinar, Dylan discusses different types of – what I would call – curriculum model. These slides show two ways of breaking down a complex skill, such as reading, into its constituent parts, like vocabulary, spelling, syntax and contextual knowledge.
What these models propose is that someone who possesses the constituent “sub-constructs” will, by virtue of that fact, also possess the super-construct. There is therefore a correlation between having good spelling and being a good reader – and that means that one can test the consistency or reliability of different test instruments testing different constructs, so long as we understand the relationship between those constructs.
Dylan says that he prefers the right-hand of these two models, which is produced by Dan Willingham. I am not an expert on teaching reading and have no opinion. I would observe, however, that it is not just a matter of personal preference. The accuracy of the model can be validated by checking its consistency against real world data. If we find many students who have good vocabulary, spelling, syntax and contextual knowledge etc., but still appear to be poor readers overall, then we shall start to doubt the accuracy of the model itself.
If, on the other hand, we can demonstrate that the model is consistent when applied to real-world data, then such models will be very useful in planning our pedagogy and in confirming the validity and reliability of our assessments. To take the extreme example discussed above, in the case that all our test instruments are off-target with respect to a particular construct, that problem will still show up because of the poor correlation between our measurements of that construct and of our measurements of the other constructs in our curriculum model.
SLIDE 62

If we view all such models as a hierarchy of learning objectives, with broad and abstract skills and dispositions at the top, and more concrete, specific, procedural skills and factual knowledge at the bottom, we will generally find that it is easier to automate assessment at the bottom of the hierarchy than at the top, where we will depend more heavily on human raters. But because we will be able to demonstrate a correlation between the top and the bottom, we will be able to build the reliability of our data, even where it assesses high-level skills, by corroborating it against the assessment data of more concrete skills. This means that we will be able to place more reliance on human raters and make more use of their unique ability to assess soft skills and dispositions. This is because we will be able to demonstrate the reliability (or unreliability) of those judgements to a greater extent that we can at present demonstrate the reliability (or unreliability) of standardised exams, when these are not corroborated against other assessment data.
SLIDE 63
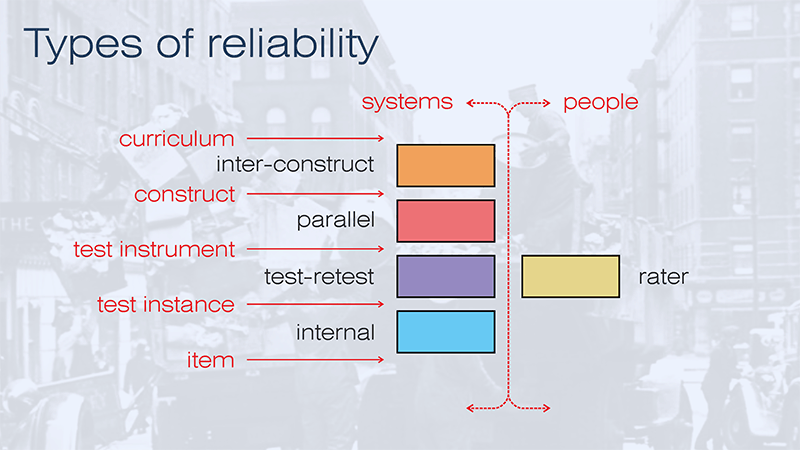
So, to return to our classification of different types of reliability, perhaps the most useful forms of reliability will be those at the top of this list: parallel and inter-construct reliability. These operate at a point at which reliability and validity become indistinguishable. Both parallel and inter-construct reliability depend on clear definitions of our constructs, or learning objectives. Unfortunately, in education, we have not produced good definitions of our constructs and the whole concept of criterion referencing has become deeply unfashionable (this is a problem that I have discussed at more length in Why Curriculum Matters). The most useful forms of reliability are therefore ones that we cannot at present use.
The importance of being reliable
SLIDE 64

A second loose end, that I left hanging from the earlier discussion of reliability, was the extent to which an unreliable test can be thought of as valid. It might be thought not because, even if the intention of the assessment was well aligned with the construct, individual test results are so dispersed that at an individual level they will often not be aligned to the construct.
SLIDE 65

However, even though the individual test results are scattered, if you have a decent number of results and you average them, then this mean is likely to be well-aligned with the target. It is therefore wrong to suggest that an unreliable test is not useful. Unreliability is not really a problem. Unreliability represents random error and random error can be cancelled out by repeat sampling. The problem we face is not the unreliability of our tests but our failure to sample repeatedly.
SLIDE 66

I have argued already that tests are rules-based systems for producing inferences. It does not follow that all inferences are produced directly by a single test. As you test the same construct repeatedly (or indeed, related constructs), you will build up an increasingly accurate super-inference, which is based on a wide spread of raw inferences. It does not make any sense to talk of such inferences as being reliable or unreliable. What interests us about our inferences is not their reliability but the confidence which we can place in them – confidence being expressed as a likelihood that the true measure of capability will lie within a certain range from what we assert.
SLIDE 67

So the key conclusion from this discussion of reliability is that we get far too wound up about it. First, unreliability is not a problem so long as we have sufficient data to average out the random errors. Second, reliability is the property of a single test instance or instrument and we should not be seeking to rely on single test instances or instruments. We should always be seeking to build up a picture of student capability through the use of multiple test instances, multiple test instruments, and multiple constructs.
Section summary
SLIDE 68

Like many popular aphorisms, “Garbage in, garbage out” is simply not true. We live in an age of recycling and big data principles mean that it is possible to build inferences in which we can have confidence from initially unreliable data, so long as we collect sufficient quantities of data, define our constructs and develop strong curriculum models. Using such approaches to improve reliability will allow us at the same time to improve validity: our ability to measure what we want to measure.
We will only be able to collect the quantity of data that we need for this approach if we can merge data from our formative and summative assessments, which is generally thought to be undesirable. This is the final counter-argument I want to address.
The purpose of assessment
SLIDE 69

One of the first blogs I wrote, back in 2012, was called Aristotle’s Saddle-Maker. It was a slightly anachronistic title because the ancient Athenians did not have saddles – Aristotle wrote about bridle-makers, which, as you can see from the hole in this guy’s hand, used to be a feature of the Elgin Marbles. But I took a liberal approach to the job of the translator and talked about saddles instead.
SLIDE 70

The saddle-maker, as Aristotle might have said, uses needle and thread and all his other tools to make a saddle. The needle and thread are the means and the saddle is the end of the saddle-maker’s craft.
SLIDE 71

While the saddle is the saddle-maker’s end, for the cavalryman it is the means of his craft, whose end is the cavalry charge. This, in turn, is the means of the craft of the general, whose end is to win victory in battle, and the military victory is the means of the craft of the statesman, whose end is the welfare of the state.
Aristotle is making a number of points here. First, that the only person making genuinely ethical choices in this sequence is the statesman – everyone else is serving instrumental purposes.
Second, those instrumental purposes mean that at each stage, purpose and quality are determined by the next person in the chain. The expertise of the saddle-maker lies in how to make a good saddle, not in what constitutes a good saddle. It is for the cavalryman to determine what sort of saddle is most effective for supporting the rider in battle. It is just the same in teaching: if you want to know what skills students need to improve their employability, ask an employer, not a teacher. If you want to know what sorts of Maths are required to continue your studies at degree level, ask a university lecturer, not a secondary school teacher. Those educationalists who have cited Aristotle’s theory of phronesis (or practical wisdom) in support of the idea that teachers should determine the purposes of their own teaching have completely misrepresented his argument.
The point that is relevant to the debate about formative assessment is that purpose is chained. The immediate purpose of the saddle-maker is to make a saddle. There are other, subsequent purposes to which a saddle can be put, but they are the purposes of other people’s crafts, or other activities or other decisions. Only in mythology is it for the saddle-maker to decide whether his saddle should be used to fight the Macedonians or the Persians.
It is true that in some circumstances, the saddle-maker might be asked to make one sort of saddle for fighting and a different sort of saddle for a working horse. In these cases, the differences will be clear in the different characteristics of the saddles being produced.
It has been argued by numerous educationalists, including Warwick Mansell, Daisy Christodoulou, Dylan Wiliam and the government’s Commission for Assessment without Levels, that formative and summative assessments have different purposes, that these purposes are incompatible, and that formative and summative assessment should therefore be kept quite separate. To ensure this separation, it is argued that the data from formative assessments should not be recorded. It is argued that formative assessment should be used to support what is commonly a decision to move on or not and that the assessment data should then be discarded, having served its purpose. It is argued that because formative and summative purposes are different, they need different sorts of assessment, and that the effectiveness of assessment will be compromised if those purposes are mixed. If this argument is right, it should be possible to point to different properties of the assessment when being used for one purpose or another.
What then are the arguments for saying that formative and summative purposes need different sorts of assessments?
SLIDE 72

First, summative assessment occurs at the end of instruction and formative assessment occurs during instruction. It follows that formative assessment cannot give you a complete picture of the state of knowledge achieved by the student at the end of the course.
Although this is true, it does not mean that assessment that occurs during instruction cannot inform a decision about the final knowledge achieved.
SLIDE 73
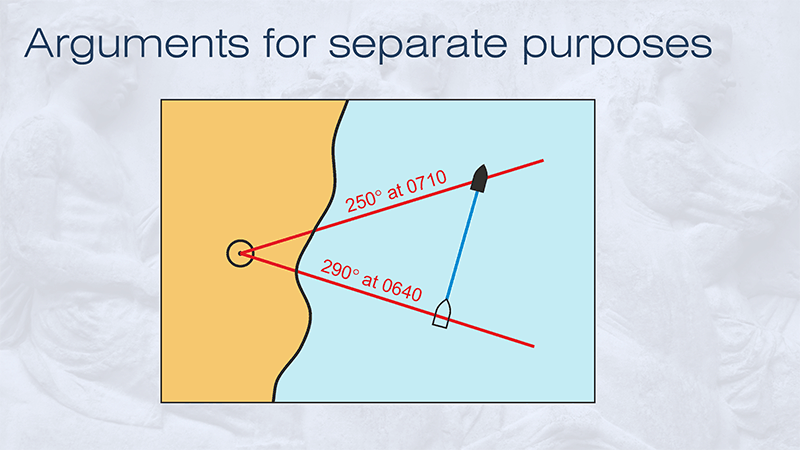
Let’s return to the sailor fixing the position of a boat by taking bearings of different landmarks. What if you only have a single landmark to observe? In that case, you need to use a technique called the running fix. Let’s say you take one bearing of your landmark at 0640 hours and a second bearing half an hour later, at 0710 hours. If you also know your speed and direction of travel between those two times, you can fix your position at 0710 hours, using the information observed half an hour earlier.
SLIDE 74

We have already established that the most effective way to build reliability is by repeat sampling. Samples taken before the end of the course can help build the reliability of any judgments made at the end of the course, particularly because the rate of student progress is generally slow and fairly predictable. Achieving consistent outcomes in this context is not about getting identical results from successive assessments, but getting results that indicate a steady rate of improvement.
The history of assessments taken during the course will increase our confidence in the terminal exam result shown by the green circle, but would undermine our confidence in the terminal exam results shown by the red circle.
Mixed with terminal assessment, formative assessment that occurs during a course can therefore serve a useful purpose in building reliable summative judgements, very much like fixing the position of a ship by using observations that were taken half an hour previously.
The reverse is not true: terminal exams cannot be used for formative purposes because they come too late.
While we are discussing the measurement of student progress, it might be a good moment to address the difficulties that Dylan and others have pointed out.
SLIDE 75

There are two main problems, one of which I think is more widely understood than the other.
The first is that if your measures of a student’s proficiency in a pre-test and a post-test, which both have a high degree of uncertainty, then the confidence that you can place in the delta – the amount of movement between the two tests – will be exponentially greater than the original uncertainty in the results of the two tests.
In the Venn diagram on the left, the large blue circle represents our level of uncertainty in a student’s score on a pre-test and the large yellow circle represents our level of uncertainty in a student’s score in a post-test. If you were to assume that both tests were perfectly accurate, they would show the student making a small amount of progress between the centre of the blue circle and the centre of the yellow circle, shown by the green arrow. Because neither test is reliable, it is almost as likely that the student in fact went backwards, perhaps by a larger amount, as shown by the red arrow which moves from a point that still lies within the blue circle of uncertainty to a point that still lies in the yellow circle of uncertainty.
A second problem, shown on the right, is that because the post-test and pre-test are correlated (meaning that students who do well on the pre-test tend to do well on the post-test), the post-test does not only measure progress but also acts as a repeat sampling of the student’s true score at the time of the pre-test. When you get a post-test that shows a significant level of progress, it has the secondary effect of raising your estimate of the student’s proficiency at the time of the pre-test, thereby reducing your estimate of the extent of progress.
Both of these problems follow from our undesirable reliance on single-test snap-shots, which lead to intrinsically low levels of reliability.
SLIDE 76

Both problems would be largely resolved if we tested continuously throughout the course, in which case we would build reliability at the same time as monitoring progress, as occurs when we draw a trend-line through a scatter graph. As it will normally be beyond the resources of most classroom teachers to do this sort of statistical analysis, we need digital analytics tools to do it for us.
SLIDE 77

A second point about continuous assessment, which needs to be made in passing, is that we generally associate continuous assessment with internal, teacher assessment; and terminal assessment with external assessment. This dichotomy is shown above by the two yellow quarters. Internal, teacher assessment has been shown to be highly unreliable, not only because teachers are not assessment experts, nor because they are not always curriculum experts either, but also because teachers are interested parties, generally wanting their students to do well – and so their assessments tend to be coloured by sub-conscious bias, if not by deliberate cheating.
For this reason, continuous assessment has become a dirty word among many assessment experts. But this is to get stuck in a false dichotomy. With education technology able to administer computer-mediated tests which use assessment algorithms that are established externally, we can now perform continuous assessment which is controlled externally.
SLIDE 78

This leads to the second reason why formative and summative assessment are thought to be incompatible. It is not just that formative assessment needs to occur during instruction, but that it needs to happen at a precise point at which it can support classroom teaching. It follows that assignment must be under the control of the teacher; and our experience of formal, summative assessments is that they are administered under the control of external bodies, who determine the time and conditions under which they should be taken.
We have already established that reliability is over-rated. Modern analytics systems can scoop up data from wherever they can find it, so long as it comes in sufficient quantity and variety to allow for post-test processing. That means that we are no longer so concerned about ensuring controlled conditions, or standardised testing, or even ensuring that everyone takes the same test. It means that the testing from which summative judgements are derived can be administered under the control of the classroom teacher, which is essential to ensure that the tests support classroom teaching in their formative capacity.
Using edtech to automate assessment is not about replacing teachers with robots or undermining their autonomy or professional status. On the contrary, it is about giving teachers the tools of the trade and the access to specialist technical support that they required to fulfil their roles as high-status professionals, without compromising their autonomy to select, modify and assign tests that are appropriate to their own teaching context.
The third argument for the separation of purposes is that formative assessment is at a lower granularity than summative assessment. Knowing that Johnnie has got a D in Maths will not tell you why Johnnie is having trouble with his simultaneous equations or why.
SLIDE 79

Much like the previous point, it is true that the outcomes of summative assessment cannot be reverse-engineered to give the teacher useful formative information. But it is not true that data at low granularity, derived from formative assessment, cannot be aggregated to create useful summative judgments. Low-granularity formative assessment data aggregates to give summative judgments but summative does not convert back to formative. If you knew exactly how good Johnnie was at simultaneous equations, and exactly why he was having trouble with them, and what his performance was on all the other constructs that composed your Maths curriculum, you would be in an excellent position, not only to modify your teaching appropriately, but also to make an evidence-based summative judgement about how good Johnnie was at Maths.
SLIDE 80

The fourth argument is that formative assessment requires less accuracy than summative assessment. I find this a strange argument, particularly when it comes from people who argue that formative assessment is one of the most effective means at our disposal of improving our teaching. If formative assessment matters, then it must also matter that it is accurate – otherwise, why bother with the assessment? Why not go for a formative throw of the dice?
Getting an incorrect grade in your summative exams may have important consequences, of course, but, unlike inaccurate formative assessment, it will not affect your education. It just means that you will walk away with the wrong bit of paper at the end of the course. In the words of Apollo 13 flight controller, Gene Kranz, it is an instrumentation problem, not a problem with the space craft.
It is the fifth argument for incompatible purposes that is normally assumed to be the most important. High-stakes assessment (which can refer either to summative assessment or assessment that is used to evaluate the teachers that are doing the teaching), high-stakes assessment causes such stress for all those involved that it produces distorted results. Either reliability is compromised because some suffer from nerves worse than others, or the curriculum is narrowed, or teachers are incited to cheat.
Yet this argument is easily refuted. All of these problems compromise an assessment in its summative or evaluative capacity just as much as they compromise the assessment in its formative capacity. Dylan gives an example of a weekly assessment that was introduced throughout a school and was supposed to serve a formative function; but it was compromised because the teachers thought that the results were being used to evaluate their own performance and therefore spent half the week teaching to the test. The test induced the teachers to narrow the curriculum, undermining its formative utility. But this problem affected the assessment’s evaluative utility just as much. It would have suggested that those teachers that spent half the week teaching to the test were the best teachers, instead of those who taught a wider and ultimately more useful curriculum. It is not as if we are designing assessments that are good for one purpose and bad for another: we are designing assessments that are bad for all purposes: formative, summative, and evaluative.
You might argue that the same assessment instrument would work well for the purposes of formative assessment but only so long as it is not used for a summative purpose. This would be like saying that a saddle would be less likely to come back hacked to pieces if is in only used for riding out on a day-trip to Athens. This is not about creating a different sort of assessment; it is just about giving one class of assessment a more sheltered life and protecting it from the detrimental effects of rough use.
There are two problems with this position.
First, it is naïve to think that your classroom teaching will not be adversely affected by the continuing inadequacy of your assessments when they are exposed to the rigours of summative use in the formal exam hall. So long as we certificate our students’ achievement and our education system is held accountable for the billions of taxpayer’s money that it is spent on it, teachers will continue to teach to the test – and if that is a thin, reductive test, then this is bound to have a damaging effect on classroom practice.
If you think that “teaching to the test” is a problem because it narrows the curriculum, then it is a problem that is easily solved. All you have to do is to make the content of your test unpredictable. Then the only way to teach to the test is to teach to the whole domain. The problem with making the test unpredictable is that it becomes very much less reliable. Student performance will vary widely depending on whether particular students have happened to study the particular content that came up in the test. If the format of the questions is also unpredictable, many students not coached in what the question requires of them are likely to misunderstand what they are being asked to do and will fail spectacularly.
It is by the occasional failure that we learn. So, while I agree with Warwick Mansell that constant and unremitting failure undermines self-confidence and motivation, occasional failure mixed with occasional success teaches us more, not only about the skills and knowledge we are studying, but also about how to deal with failure. A learning environment of vivid success and failure is more interesting, more challenging, and formatively speaking, more productive than one of a constant, grey diet of beta minuses, scored on predictable tests.
If we believe in the desirability of unpredictable tests (and I think we should), then we we must also accept the desirability of unreliable testing. And if we want to make justified inferences on the basis of unreliable tests, then we are brought back to the necessity of repeat sampling.
Second, the people who make this argument have no reason to suppose that our formative assessment will prove adequate when it is freed from summative duty. They have every reason to suppose the opposite, when they specifically recommend that data is discarded and we should continue to rely on single-test snapshots, which we have seen to be intrinsically unreliable. The only benefit (if benefit it is) of recommending that all formative data is discarded, is that formative assessment then becomes so ephemeral that, like some sub-atomic particle that only exists for nano-seconds, the extent of its unreliability becomes invisible to the human eye. It is an exercise in sweeping our problems under the carpet.
SLIDE 81

If you think that I must be wrong to say that summative judgments can be built from formative assessments, simply because I am the only person saying it – then you might be interested to know that plenty of very reputable people have said the same as I am saying now.
The Task Group for Assessment and Testing (TGAT), Chaired by Professor Paul Black, which produced a extremely thoughtful report in 1987, stated that “It is possible to build up a comprehensive picture of the overall achievements of a pupil by aggregating, in a structured way, the separate results of a set of assessments designed to serve formative purposes”. Dylan Wiliam says the same: “One can always take the fine-scaled data that is useful for teaching and learning, and aggregate it for summative purposes”. David Bell, the PUS at the DfES in 2008, told the Commons Select Committee that “While I hear the argument that is often put about multiple purposes of testing and assessment, I do not think that it is problematic to expect tests and assessments to do different things”. These are all reputable figures and I have never seen their positions coherently refuted. All that has happened is that we have been taken over by a massive episode of group-think, in which formative and summative assessments are presumed to be incompatible, for no good or defensible reason.
SLIDE 82

Just as the Athenian saddle maker has a single purpose in making a good saddle, so all assessments have a single immediate purpose in discovering what the student knows. That is done well, not when we isolate and separate test data, but when use what might be initially unreliable tests, subsequently building confidence by aggregating data from multiple sources and repeat sampling.
The problem with distortions caused by high-stakes testing remains to some extent, of course, but I suggest that this can be easily solved, if we think of the problem in a different way.
SLIDE 83

If you are working in aerodynamics, you will want to keep things smooth. Sharp edges, like the top of the windscreen on this soft-top, create turbulence. You could think of this sharp edge as representing the C/D boundary at GCSEs, which distorts the priorities for schools who want to do well in the national league tables. You could also think of a high-stakes assessment as a sharp edge or an irregularity in a surface. The problem is not the high-stakes in itself: the problem is that everything else is low-stakes. It is the difference that creates the irregularity.
Keeping everything smooth means assessing everything, all the time and using all your assessment data for all purposes equally. Some assessments will be based on teacher judgement, much can be automated by edtech, some will be based on self-assessment, peer assessment, parent assessment; some will be based on traditional tests in controlled conditions. The tests will be varied, challenging, interesting: we will be able to make them like this because we will not be obsessed with the reliability of the test. It will be very difficult to game the tests because they will be happening all the time and they will be indistinguishable from the constant practice through which our students will be learning.
It is through the use of data analytics systems that this wealth of assessment data will be aggregated, compared and correlated, building inferences about student capability in which we can have confidence. The continuous nature of this assessment will not detract from teaching: it will enhance it. It will build understanding by encouraging and managing spaced practice, varied practice, and adaptive remediation. It will enable us to place more emphasis on higher-level understanding and character education.
SLIDE 84
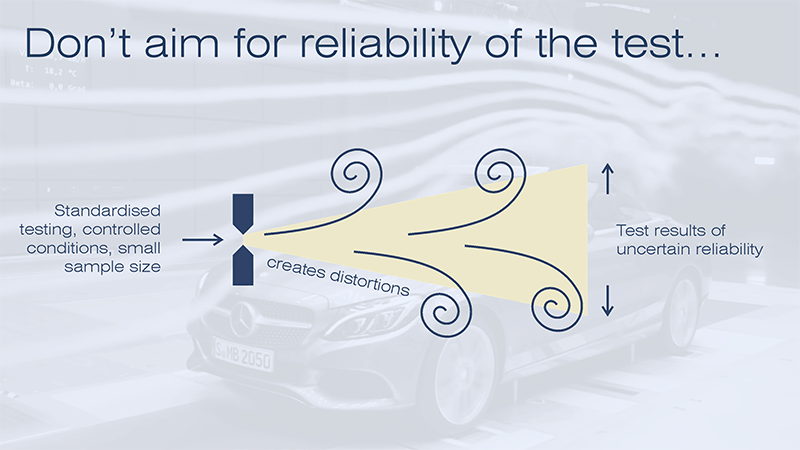
In our current approach to assessment, which both in summative and formative contexts is based on single-test snapshots, the low sample-size reduces confidence levels. In the case of summative assessment, the controlled conditions and high stakes consequences create distortions, which I have compared to turbulence, decreasing reliability and confidence. We end up with what we began with: the results from a single test which is probably unreliable but, being single, we are unable to measure how unreliable it is.
SLIDE 85

We should stop trying to build reliability into the front end of our assessment system by the exclusive use of standardised testing in controlled conditions. Instead we should build reliability and confidence by the use of digital analytics, corroborating and modelling our test results, discarding outliers, and ending up with inferences based on a wide evidence-base and associated with clearly-stated confidence levels.
SLIDE 86

My proposal that we should test everything, all the time, depends on the use of digital technology to capture test outcomes, to model curricula, and to do the analytics. Of course, we do not yet have that digital technology and those educationalists whom I criticise might (and do) reply that they are interested in living in the world as it is, rather than in imagining the world as it might be. The trouble is that if you never imagine how the world as it might be, you will never improve it. Instead of fixing our dysfunctional assessment system, you will merely learn to cope with it.
SLIDE 87

Let me finish by drawing some general conclusions.
SLIDE 88

Our thinking is limited by a large number of false assumptions, which may appear justified in the particular, dysfunctional circumstances in which we find ourselves, but which are neither justified in a wider context, nor useful because they prevent us from seeing how our poor practice could be improved.
It is wrong to think that testing is a distraction from teaching – on the contrary, testing is one of the most important techniques of good pedagogy.
It is wrong to over-value reliability. Unreliability can always be corrected, given enough varied and meaningful data.
It is wrong to assume that large sample sizes are unaffordable – partly because expensive summative assessments are unnecessary, partly because large amounts of assessment can be automated, and partly because the assessment can be performed in the course of good teaching, which is what we need to be doing in any case.
It is wrong to assume that tests to not measure anything and that we have to rely on expensive and generally unreliable human raters for more than a small proportion of our assessments.
It is wrong to assume that it is impossible to describe our learning objectives without being reductive.
It is wrong to think that formative, summative and evaluative purposes of assessment are incompatible.
SLIDE 89

If we are to sort out our dysfunctional assessment system, we need to abandon these assumptions.
We must not turn away from practice, feedback and assessment. We must not be tempted to think that because we do testing badly, testing is therefore a bad thing to do.
The only way that we can test everything all the time, the only way that we can model the curriculum and make sense of our data is by building capable digital education technologies. It is not within the scope of this essay to propose how this can be done – but I shall be publishing a paper in the coming months to explain what role I believe government should be playing to enable this development to occur.
SLIDE 90

What I am proposing is nothing less that the radical and complete transformation of the way we run our education system. I know that most people who propose radical and complete transformations are regarded as lying somewhere on a spectrum between harmless but deluded eccentric and lunatic.
If you draw that conclusion in my case, bear in mind that this is a radical transformation that the rest of the world is already embarked on. It is not me who is out of step: it is you, collectively, the education system. If you can find a flaw in my arguments, then please make the case that I am wrong. But do not dismiss them merely because you perceive me to be a lone voice, because I am not.

Great body of work – perhaps we need to link up your work on assessment and what I’m doing on curriculum and start joining the circle
I don’t believe you read it that quickly, Peter! 😉 But thank you anyway and yes – let us meet and discuss soon. I am up to my eyeballs till the end of the month but let me DM you in early August. Best, Crispin.
I have skim read and focused on the sections that were of particular interest, especially your refutation of those experts who argue against the links between the types of assessment and the validity of testing and your conclusions which I liked. I think I got the gist, but I agree it will need a proper read later. I’ve extracted a few quotes for my website also. And yes, You’re surely not alone.
I’m impressed!
Hi!
Have you read “Progressively worse: The burden of bad ideas in British schools”? If so: I would love a post on it.
Hello Ardfinn,
Sorry, I missed your question. Yes, I read Progressively Worse some time ago and have met Robert Peal a few times – I saw him last at a panel discussion at Policy Exchange led by Nick Gibb on textbooks – Robert is writing a very good series of History textbooks.
I think Progressively Worse is a great book in a very respectable tradition of polemics, and I am sympathetic to its general stand against barmy progressive teaching ideas.
One point that I remember agreeing with Robert about is that many of the knowledge-based curriculum people (e.g. Daisy Christodoulou and David Didau) have unfairly criticised Bloom’s taxonomy on the basis that it puts knowledge at the bottom of the hierarchy, when in fact Bloom was trying to represent teaching as a process in which knowledge is the foundation of everything else. The foundations are no less important for being at the bottom of the building.
However, it is true that if propositional knowledge is the foundation, the start, that is important, but it does not mean that mastering large numbers of facts is the summit of the educational endeavour. It is the raw material out of which more complex skills and understandings (which of course are also knowledge) are developed. The building up of more complex knowledge is done by practice-feedback cycles.
My reservation about the textbook movement (in which Robert is a key player) is that it is all very well but still leaves this heavy lifting to the teacher, who may find it difficult to cope with the work overload involved in managing this practice-feedback cycle.
My second divergence (and the only criticism that I can remember of Progressively Worse) is that I think Robert was unfairly critical of discovery learning. Greg Ashman is another critic of discovery learning. I don’t think that this theory implies that students are free to “discover” (i.e. make up) their own knowledge, or that they should be made to take a long time to acquire knowledge that could be given to them on a plate much more quickly. I think the value of the theory is that students should be forced to do the hard thinking of working out problems for themselves, which is the only way that we will really understand the structure of knowledge. I remember that when I did Nuffield Physics in the 1970s, I felt that a drawback of the course was that we were never told what the answer was – which I think is to take the approach to an undesirable extreme. But I think that is good pedagogy to try and get students to discover knowledge, in the sense of working it out for themselves, before then telling them the answer.
In short, I think the problem with the proponents of the knowledge-based curriculum is that they make it sound as if teaching is really pretty easy – just a matter of telling it as it is and learning the right vocab / dates etc – when really it is a matter of building complex mental models, which is hard work. I see discovery learning, properly implemented, as a way of getting students to engage with that difficult task.
Everything else about Progressively Worse I thought was great. Being a polemic, though, means that although it does the job of hitting its target, it doesn’t attempt to tell us what one should do instead. And there is the rub.
Will that do, as a sort of micro-post? 🙂
Thank you very much!
Having first hand knowledge with teaching in high schools, it’s not difficult to sympathise with british teachers, though the situation is generally far less extreme in Norway.
Since completing Peal, I’ve been trying to read as much as possible about Direct Instruction and Zig Engelmanns ideas on teaching.- Could that be a way forward? They seem to have great results on math-, reading- and writing skills, particularly for the youngest learners.
The education establishment seem generally hostile towards DI, and the DI community appear a little bit like a cult to me. I’m finding it a bit of a challenge sorting through the polemic and arguments and trying to find out what useful information can be extracted: If students do learn to read and write and do math faster with DI, then maybe that could be a reasonable foundation.
It looks to me as if we can teach students to read and write, and do arithmetic well (a good bit of automated knowledge needed here) early on, then it matters less how we teach later on. Catch them early, so to speak. So if DI does that better and faster than other methods, then why aren’t we all doing it? Unless something else is more important (as Peal would argue)…
What do you suggest, then? A return to boarding schools, uniforms and the strictness of the early 20th century looks unlikely. In Scandinavia there is no tradition of this in any case.
Data driven and data informed teaching still looks far away, and each teacher is about as isolated as ever. We’re three decades into ICT (for lack of a better term) in schools, and we’ve not made any progress when it comes to improving learning and retention. PISA scores are about the same as they’ve been for 20 years – in some cases they’re worse now than 15-20 years ago. Where is your startup that fixes this, Crispin? 🙂